در پست پیشین، یعنی قسمت اول داستان برنامهنویس شدنم (لینک) از زمانی که شروع به خوندن کتابهای ویژوال بیسیک کردم تا زمانی که پروژه جبیر رو راه انداختم رو به تفصیل توضیح دادم. فکر میکنم داستان برنامهنویس شدن من، داستان جالبی برای خیلی از دوستانی که وبلاگم رو میخونن بوده و به همین دلیل، تصمیم گرفتم که قسمت دومش هم حتما بنویسم.
همونطوری که در قسمت قبلی قولش رو داده بودم، قراره که در این قسمت از بعد از پروژه جبیر تا زمانی که وارد بازار کار شدم رو توضیح بدم و بگم چی شد که اینطوری شد. در مورد مسیرهای شغلی قبلتر توضیح دادم (مثلا در پست چگونه توزیع لینوکس بسازیم و یا پست چگونه بازیساز شویم) همینطور حتی ابزارها و وسایلی که در مسیر شغلهای مختلف طراحی و تولید کردم (مثل صداگذاری روی بازی کامپیوتری) هم در این وبلاگ پیشتر توضیح دادم. فلذا در این مطلب، اصلا و ابدا به مسیرهای شغلی اشاره نخواهم کرد.
ورود به دانشگاه
در طی این سالها، یعنی از حدود ۹۱ تا ۹۳ راههای زیادی رو رفتم که سرویسها و نرمافزارهای خاصی رو طراحی کنم و خب دروغ چرا، تا حد زیادی هم رویای استیو جابز یا زاکربرگ شدن هم در سر داشتم و خب کارهای مختلفی مثل ایجاد انجمنهای اینترنتی مختلف (ایرانبیاسدی، ایرانهکینتاش و …) گرفته تا برپا کردن شبکههای اجتماعی و نرمافزارهای آنلاین دیگر (اکسوال، نکستکلود و …) رو انجام میدادم. راستش این راهها من رو به قول خارجیها Satisfy نمیکرد و همچنان دنبال این بودم که یک سیستم عامل خوب بسازم!
خلاصه شد سال ۹۲ و ما از شهر بندرعباس به تهران برگشتیم. اون سال، سال پیشدانشگاهی من بود (و بد نیست این داستانکم رو هم پیرامونش بخونید) و اون سال، یک تصمیم بزرگ هم گرفتم. تصمیمم این شد که جبیر به جای این که مبتنی بر اوبونتو (یک توزیع از گنو/لینوکس)، یک نسخه شخصیسازیشده از FreeBSD باشه. از همین رو، شروع کردم به رفتن به IRC های مختلف، سوال پرسیدن و مستندات خوندن. بعد از چندین ماه مطالعه، وضعیت اینترنت خونه و خودم تا حد خوبی پایدار شد و بعد شروع کردم به انجام تغییرات روی کد FreeBSD.
بعد از مدتی، پروژه جبیر تا حد خوبی پیش رفت و گذشت و گذشت و من کنکور دادم (داستانی از کنکور هم اینجا نوشتم) و وقتی نتایج اومد، فهمیدم که در دانشگاه آزاد اسلامی واحد تهران مرکز در رشته مهندسی کامپیوتر و گرایش سختافزار قبول شدم.
شرکت در لاگها و رویدادها و آخر و عاقبت پروژه جبیر
حضور در تهران و دانشجو شدن، به من کمک کرد که وارد جامعه بشم و در رویدادهای نرمافزار آزاد و متنباز و سایر رویدادها (مثل PyCon و …) شرکت کنم. اولین رویدادی که شرکت کردم، رویدادی بود به اسم «جامعه رایانش ابری آزاد». در اون رویداد با KVM و Docker آشنا شدم و تا حد زیادی هم دانشم در زمینه Containerها و مجازیسازی تا حد خوبی بالا رفت.
در حاشیه شرکت در این رویدادها، بسیاری از افرادی که از انجمن اوبونتو و یا تکنوتاکس یا لینوکسریویو میشناختم رو حضوری دیدم و باهاشون آشنا شدم و حتی رفاقتهایی شکل گرفت. پس از مدتی، در بحثی دوستانه، تصمیم بر آن شد که پروژه جبیر کلا منحل بشه و پروژهای به این بزرگی که نیازمند دانش فنی بالا، پول زیاد و همچنین حوصله فراوونه، به زمانی موکول شه که بتونم از پس حداقل یک موردش بربیام. فلذا پروژه جبیر اعلام شد که دیگه قرار نیست ادامه پیدا کنه.
اگر دوست دارید ببینید که پروژه جبیر چه شکلی بوده، میتونید این لینک مربوط به وب آرکایو رو هم ببینید: لینک. در ادامه، بنا به دلایلی (که در ادامه این مطلب بهش میپردازیم) تصمیم شد که پروژه جبیر بیشتر روی فاز سختافزاری باشه و چند مطلب هم در موردش حتی نوشتم(لینک).
یادگیری روبی، ورود به حوزه سختافزار و دیگر هیچ!
مهرماه ۹۳ بود که من خیلی جدی تصمیم گرفتم حداقل یک زبان برای توسعه وب رو جدی یاد بگیرم. قبلترش، کتاب «از این پس پایتون» رو خونده بودم و به همین خاطر هم کمی با پایتون و فلسک آشنا بودم. دوستی یک کتاب جنگو هم برای من ارسال کرد. اما در همون هنگام در بحثی در IRC که دقیق یادم نیست مربوط به occc بود یا لاگ کرج، دوستی به من پیشنهاد کرد که روبی و روبیآنریلز رو یاد بگیرم. در ادامهش، توصیه کرد که حتما با دیتابیسها آشنا شم و کمی هم مهندسی نرمافزار یاد بگیرم.
من هم این توصیه رو عملی کردم و شروع کردم به خوندن روبی. شاید باورتون نشه ولی از اونجایی که دیدم زبون روبی، خیلی در ایران زبون روتینی نیست و خیلیها باهاش غریبهند، تصمیم گرفتم دانش خودم رو در قالب یک کتاب الکترونیکی دربیارم و خب نتیجه پس از مدت نسبتا طولانی شد کتاب آموزش روبی که به رایگان قابل دانلوده.
خب همونطوری که ابتدای متن گفتم، من گرایش سختافزار بودم و حقیقتا این وسط به سرم زده بود دانش سختافزاری خودم رو هم بالا ببرم. به همین خاطر ترم ۳ یا ۴ که بودم، قبل از این که به مدار منطقی برسم، خودخوان شروعش کردم. برام جالب بود و خب در عین حال ریاضیات گسسته هم برای من داشت مرور میشد. این مرور، در کنار دانش مدار منطقی من رو وادار کرد که کمی بیشتر بخوام در این حوزه ورود کنم. به همین خاطر، معماری کامپیوتر و ریزپردازنده رو هم حتی پیش از این که درسم بهشون برسه، مطالعه کردم.
وقتی به نتایج جالبی رسیدم، تصمیم گرفتم دوباره دانشم رو با مردم به اشتراک بذارم. به همین خاطر، این بار هم محتوا رو به زبون انگلیسی تولید کردم (لینک) و به رایگان در نسخه انگلیسی همین وبلاگ منتشرش کردم. خلاصه که اینجا تموم نمیشه. در اون سالها، بازار «اینترنت چیزها» یا IoT هم داغ بود و خب طبیعتا شروع کردم به یادگیری آردوینو، رزبریپای و … و پروژههای جالبی هم با اونها انجام دادم. البته خیلی از این پروژهها رو هنوز که هنوزه عمومی نکردم.
خلاصه این مورد هم گذشت و رسیدیم به شهریور ۹۶. یعنی جایی که من خیلی جدی و رسمی وارد بازار کار شدم.
ورود به بازار کار
در تیرماه ۹۶، در رویدادی شرکت کردیم که مرتبط با فعالان صنعت بازی رایانهای بود. این رویداد، به طور خاص به آهنگسازان و مهندسین صدا اختصاص داشت و خب بخاطر علاقه شخصیم به موسیقی، در این رویداد شرکت کردم. آخر رویداد گپ و گفتی با سخنران رویداد داشتم که باعث شد شخصی بیاد خودش رو معرفی کنه و بگه که تیمشون نیاز به آهنگساز داره. پس از مدتی، مدیر استودیو به من پیام داد و گفت بازیای در ژانر کودکه و خب نمیدونم چی شد که اون موقع، این بحث ادامه پیدا نکرد.
اما شهریور ۹۶ یکی از دوستانی که در همون استودیو مشغول بود، برای یک بازی دیگر من رو دعوت کرد به همکاری. یک مصاحبه ریزی داشتیم و پس از اون مصاحبه، قرار شد من برم و همکاری کنم. پس از این ماجرا، من رسما وارد اکوسیستم و بازار کار شدم تا به امروز.
سخن آخر
خب، در این مطلب هم مثل مطلب قبلی حجم خوبی از خاطرات من رو شاهد بودید. کل حرفی که میخواستم بزنم این بود که دوستان، از تجربه کردن و حتی شاخه شاخه پریدن؛ نترسید. این پرشها به خودی خود باعث میشن که شما در کارتون – حتی کارهای فریلنسری و پروژهای – به شدت موفقتر عمل کنید. یادتون باشه که زندگی، فانتر از اونیه که بخواید با زیادی جدی گرفتن؛ خرابش کنید.
مدت زیادیه که در نظر دارم مطلبی در مورد این که چطور برنامهنویس شدم رو قلمی کنم. مطالبی از این دست، نوشتنشون بسیار سختتر از چیزیه که فکرش رو هم بکنید. چرا که باید به گذشتههای دور سفر کنیم و خیلی از خاطرات گذشته رو هم مرور کنیم. بخصوص وقتی قراره در مورد چیزی مثل همین برنامهنویسی، بنویسیم. من قبلتر در همین وبلاگ، در مورد این رشته کامپیوتر چیه توضیح داده بودم (لینک). زمانی که اون پست رو نوشتم، فکر کنم دمدمای اعلام نتایج کنکور سراسری بود و طبیعتا خیلیها، دوست داشتن که با رشته تحصیلیشون آشنایی پیدا کنند. خلاصه، خواستم در این پست هم چیزی شبیه به همین موضوع بنویسم ولی با خودم گفتم بهتره که در مورد «داستان برنامهنویس شدن خودم» پست بنویسم.
من کی هستم؟
من محمدرضا حقیری هستم. احتمالا خیلیها من رو از «پروژه جبیر» بشناسن. اگر ماجرای پروژه جبیر رو نمیدونید، باید بگم که شاید یکی از اولین پروژههای جدی من بود که خیلی استارتاپگونه پیش میرفت. اطلاعات بیشتری از این پروژه رو میتونید از این لینک بخونید. اما الان چطور؟
فکر کنم پس از حدود ۱۰ سال حضور مداوم در جامعههای مختلفی مثل نرمافزار آزاد، جامعه فارسیزبان اوبونتو، جامعه Open Street Map (که البته در این آخری حضورم خیلی کمرنگتر بود) و جامعه بینایی ماشین (لینک) دیگه الان بدونید که شخص «محمدرضا حقیری» یک برنامهنویسه که دستی بر لینوکس، BSD، پایتون، کمی سختافزار داره و تبحر خاصی هم در تپه نوردی!
اگر دوست دارید بیشتر از من بدونید، در روزی که این پست نوشته شده (یعنی ۱۱ مهر ۱۴۰۰ هجری خورشیدی)، من چندین ماه از بیست و ششمین سال زندگیم میگذشته و در حال کار روی یکی از پروژههای خیلی جدی بودم و این پست رو برای این نوشتم که این داستان رو با شما به اشتراک بذارم. خب، من رو شناختید؟ بیایید بریم سراغ داستان برنامهنویس شدنم.
شروع برنامهنویسی
ما یک سری کتاب برنامهنویسی ویژوال بیسیک ۶ (لینک) در کتابخونه داشتیم. فکر کنم اواسط یا اواخر سال ۸۶ بود که من شروع کردم به خوندن یکی از این کتابا. برام خیلی جالب بود که چطور اینقدر این زبان هلوئه 🙂 از اون جالبتر این که اون زمان Windows Form هم چیزی بود که خیلی رو بورس بود و خیلی از برنامهنویسها ازش استفاده میکردند. یادمه که همون دوران، شرکت «پرند» هم یک مجموعه به اسم «کینگ» داشت (و البته فکر کنم هنوز هم داره) که درونش هزاران نرمافزار وجود داشت.
در یکی از دیسکهای کینگ، یک کتگوری Programming بود که ذیل اون، ویژوال استودیو قرار داشت. یادمه که با استفاده از دیسک مربوطه، ویژوال استودیو رو نصب کردم و شروع کردم به پیاده کردن چیزایی که در اون کتاب نوشته بود. یک فرم ساختم و یک لیبل زدم و روی لیبل نوشتم Hello World و شاید ندونید؛ ولی اون لحظه حسی که داشتم با حس آرمسترانگ وقتی رسیده بود روی ماه برابری میکرد. خلاصه که بعد از این که دورهای افتخار رو زدم، نشستم به خوندن باقی کتاب. اما میدونید چی شد؟ کتاب با VB6 آموزش میداد و فکر کنم من ویژوال استودیو ۲۰۰۵ و چنین چیزی رو داشتم.
خیلی دنبال فایل نصبی و حتی دیسک ویژوال بیسیک ۶ گشتم اما چیزی نیافتم. خلاصه در همون دوران بود که با انتشارات کلید آموزش (لینک) آشنا شدم. اولین کتابی که ازشون خوندم «کلید فتوشاپ» بود. در لیست کتابهاشون گشتم و دیدم که «کلید ویژوال بیسیک» هم دارند. اون کتاب رو خریدم و شروع کردم به خوندن و یادگیری از روی اون. خلاصه، بعد از چند ماه کشتی گرفتن، با ویژوال استودیو یک عدد ماشین حساب ساختم و دیگه شما میتونید حدس بزنید چقدر خوشحال بودم.
خلاصه که سال تحصیلی بعدیش، من تا حد خوبی روی مهارتهای توسعهدهندگیم کار کردم. البته خیلی از ابزارهایی مثل Multi Media Builder که استفاده میکردم، ابزار برنامهنویسی محسوب نمیشدند، اما خب بهرحال برای این که در جشنوارههای دانشآموزی و … شرکت کنم، بد نبودن. خلاصه که گذشت و گذشت و گذشت و رسیدیم به سال سوم راهنمایی. سوم راهنمایی من، سال جنجالی ۸۸ بود. سالی که تا حد زیادی افراد برای آینده خودشون، نگران شده بودند و طبیعتا من و خانواده من هم از این قاعده مستثناء نبودیم.
در این سال، یه جو قشنگی روی مدرسه حاکم شده بود. به طرز عجیبی مدرسه ما، دوست داشت که قطب تولید نرمافزار دانشآموزی باشه، قطب رباتیک منطقه خودش باشه و … . حقیقتا من این فرصت رو غنیمت شمردم و با همون ابزارهایی مثل Multi Media Builder نرمافزارهایی برای درسهای علوم و عربی ساختم. خیلی از فرمولها و روشهایی که در کلاس ریاضی یادمون میدادن رو با ویژوال بیسیک تبدیل به نرمافزار میکردم. در همین حین، به سبب تمرکز مدرسه روی مسابقات دانشآموزی رباتیک، سی++ هم تا حد خوبی یاد گرفته بودم. از طرفی انتشارات کلید هم «کلید دلفی» رو منتشر کرده بود و این یعنی که در حال یادگیری دلفی هم بودم.
شاید بگید چقدر هندونه؟ خب این همیشه روش من بوده. همیشه هم نتیجه داده و همیشه هم ازش راضیم 😁. شاید بد نباشه که اشاره کنم که همزمان با این ماجرا، به سبب داشتن وبلاگ روی بلاگفا هم کمی جاوااسکریپت (زمانی که جاوااسکریپت هنوز انقدر گسترده نبود) یاد گرفته بودم …
شروع پروژه جبیر
حالا دیگه دبیرستانی شده بودم و دانش خوبی در زمینه برنامهنویسی داشتم. اما خب یک مساله خیلی مهم پیش آمده بود، از تهران مهاجرت کرده بودیم بندرعباس (که به نظر من یکی از زیباترین و دوستداشتنیترین شهرهای کشورمونه) و در بندرعباس هنوز دوست پایهای نداشتم که با هم نرمافزار و ربات و اینا بسازیم. پس باید چی کار میکردم؟ حقیقتا سال اول دبیرستان رو مجددا مشغول توسعه مهارتها و دانشم شدم. اما پس از گذروندن سال اول، مدرسهم عوض شد و اونجا با دوست جدیدی آشنا شدم.
اما حالا صحبت دوست جدید بمونه برای بعد، در تابستانی که بین سال اول و دوم دبیرستان داشتم، یادمه یک شماره از «مجله دانشمند» رو خریدم که در اون، کتاب «طراحی و پیادهسازی سیستمهای عامل» از «اندرو تننباوم» رو معرفی کرده بود. نکته اینجا بود که انتهای اون مقاله، در مورد لینوس تروالدزِ، خلق لینوکس و دعواهای معروفش با اندرو تننباوم هم نوشته بود و من اینجا جرقهای در ذهنم زده شد. من باید سیستمعامل میساختم! پس از گذشت چند ماه و مهاجرت به لینوکس و تحقیق در موردش و همچنین غرق شدن در دنیای اپل و زندگی شخصی استیو جابز و … (شاید بشه گفت جوگیریهای رایج دوره نوجوانی) بالاخره به این نتیجه رسیدم که بهتره که پایه سیستمعامل من هم لینوکس باشه.
بعد از مدتی، به ذهنم رسید که به کامیونیتی اوبونتو مراجعه کنم و اونجا بپرسم. به همین خاطر این پست رو ایجاد کردم و یه سری سوال پرسیدم. احتمالا در همون تاپیک بتونید راهنماییهای دانیال بهزادی رو ببینید که خب بعدتر در پروژه مشابهی حتی با هم همکاری هم کردیم 😂
بگذریم، بهار ۹۱ یک نسخه کاستومشده اوبونتو به اسم «جبیر او اس» منتشر شد که از قضا یک پروژه جنجالی هم شد. اما اثرات جانبی جالبی هم داشت. شاید بتونم مهمترین اثرش رو «ورود رسمی به جامعه نرمافزار آزاد» بدونم، اثر دیگرش هم این بود که مدیر مدرسه ما گیر داد که الا و بلا شما باید بیای این رو ببری جشنواره خوارزمی 🙂 بردیمش جشنواره خوارزمی ولی اونجا مقبول نیفتاد. حالا ماجرای خوارزمی رو یک بار باید اساسیتر تعریف کنم که در مقوله این مقاله نمیگنجه.
خلاصه پروژه جبیر تا حدود ۹۴ ادامه داشت و بعدش به کل رفت به تاریخ پیوست. دلایل متعددی هم داشتم براش، اما خب فعلا تا همین جاش رو قبول کنید ازم.
و این داستان ادامه دارد …
اول که شروع کردم به نوشتن این داستان، فکر میکردم که میتونم در یک پست جمعش کنم، ولی دیدم که خیلی پیچیدهتر از این حرفاست و شاید ۳-۴ قسمت ازش دربیاد. اما خب در کل، قصدم اینه که تا زمانی که وارد بازار کار شدم رو برای شما تعریف کنم (یعنی دو پست نگهش دارم) و بعدا سر فرصت مناسبی، تجربیات کاری خودم هم باهاتون به اشتراک بذارم.
پس، فعلا این پست رو از من داشته باشید و منتظر قسمت بعدی باشید، قسمت بعدی احتمالا خیلی جذابتر خواهد بود 😁
مدتی میشه که در جامعه بینایی ماشین، دارم به صورت خیلی جدی در مورد بیناییماشین و ملزوماتش، تولید محتوا میکنم. از همین رو، تصمیم گرفتم که در قالب این پست وبلاگی، در مورد این که بینایی ماشین چیه و کجا کاربرد داره و چرا باید بلدش باشیم و از کجا باید شروع کنیم؛ بنویسم.
این مطلب، اصلا و ابدا قرار نیست «آموزش» باشه و همونطوری که ابتدای مطلب گفتم، صرفا «نقشه راه» برای شماست.
بینایی ماشین چیه؟
بینایی ماشین در واقع یکی از شاخههای علوم کامپیوتر محسوب میشه که هدفش، اینه که پردازش و درک تصاویر دیجیتال رو سادهتر کنه. بینایی ماشین در ترکیب با هوش مصنوعی، رباتیکز و سایر شاخههای مرتبط با علوم و یا مهندسی کامپیوتر، میتونه به بهبود زندگی افراد کمک شایستهای کنه.
شاخههای زیادی برای بینایی ماشین داریم اعم از تشخیص چهره، تشخیص متن، خواندن نویسههای نوری (OCR)، واقعیت افزوده، واقعیت مجازی و … . هرکدوم از این شاخهها، تخصصهای خاص خودش رو میطلبه که در ادامه مطالب بهش خواهیم پرداخت.
کجا کاربرد داره؟
کاربردهای بینایی ماشین، میتونه در بسیاری از جاها باشه. نمونهش مثلا همین پروژهای که من زده بودم:
همونطور که میبینید، این پروژه برای اندازهگیری اشیاء مختلف با کمک بینایی ماشین ساخته شده بود. همچنین، یک پروژه دیگر این بود که حروف اشاره (که مورد استفاده ناشنوایانه) رو تشخیص میداد. در دنیای امروز تقریبا در هر جایی که کوچکترین استفادهای از تصویر میشه، مثل ویرایش و ساخت تصویر؛ تشخیص اقلام درون تصویر و …؛ بینایی ماشین داره در ابعاد وسیعی استفاده میشه.
چرا باید بلدش باشیم؟
بایدی وجود نداره. یادگیریش به عنوان یک مهارت، کاملا میتونه شما رو به یک پروژه خفن، کار یا پول نزدیک کنه. حتی اگر قصد ندارید در این زمینه کار کنید هم میتونید با یادگیری بینایی ماشین به سادگی برای خودتون یک تفریح سالم بسازید.
از کجا شروع کنیم؟
خب مهمترین بخش این مطلب دقیقا همینجاست که قراره با هم یاد بگیریم که چه پیشنیازهایی برای یادگیری بینایی ماشین وجود داره. هر پیشنیاز رو با هم کمی بررسی خواهیم کرد 🙂
برنامهنویسی پایتون: از اونجایی که پایتون زبان سادهایه و اکثر آدمها دنبال یادگیریشن (و این یعنی منابع آموزشی خیلی خوبی براش هست) بهتره که پایتون رو تا حد خوبی یاد بگیرید. حد خوب، یعنی حدی که شما بتونید یک نرمافزار ساده ولی کاربردی رو باهاش توسعه بدید (مثلا یه ماشین حساب یا چیزی مشابه اون).
مقدمات یادگیری ماشین: بینایی ماشین به شکلی یکی از زیرمجموعههای هوش مصنوعی محسوب میشه. این نشون میده که اگر شما به الگوریتمها و تئوری یادگیری ماشین و … آشناییت کافی داشته باشید، میتونید در این فیلد هم پیشرفت قابل توجهی کنید. گذشته از این، یادگیری ماشین میتونه بهتون در «هوشمندسازی» بیشتر نرمافزارهای بینایی ماشین کمک کنه.
آشنایی مختصر با جاوا یا سی++: از اونجایی که پایتون یک زبان مفسری محسوب میشه، ممکنه خیلیجاها (مثلا در یک برد آردوینو) نتونیم مستقیم ازش استفاده کنیم و همچنین استفاده ازش پیچیدگی خاصی به همراه داشته باشه؛ بهتره یک زبان سطح پایینتر مثل سی++ هم کمی آشنا باشیم. همچنین اگر قصد این رو دارید که اپلیکیشن تلفن همراه بنویسید که از بینایی ماشین استفاده میکنه، بد نیست دستی هم در جاوا داشته باشید.
آشنایی با سختافزارها و سیستمهای نهفته (Embedded Systems): یکی از کاربردهای عظیم بینایی ماشین، فعالیتهای Surveillance میتونه باشه (البته این که این فعالیتها بد یا خوب هستند بحث جداییه). یکی از نمونههاش میتونه «سیستم حضور و غیاب با تشخیص چهره» باشه، یا حتی «دفترچه تلفن هوشمند» و … 🙂 به همین دلیل، بد نیست که کمی با سیستمهای نهفته و سختافزارهایی مثل Jetson Nano و Raspberry Pi آشنایی داشته باشید.
آشنایی با لینوکس: این واقعا نیاز به توضیح خاصی نداره، روایت داریم اگر لینوکس بلد نیستی، برنامهنویس نیستی 🙄
لیست بالا به شما کمک میکنه که محکمتر در زمینه بینایی ماشین، قدم بردارید. هرجاش رو که بلد نباشید میتونید با جستجو پیداش کنید و یاد بگیرید و از یادگیری، لذت ببرید 🙂
سخن آخر
از این که وقت گذاشتید و این مطلب رو خوندید ممنونم. در آینده، در قالب پستهای وبلاگ در مورد پروژههای بینایی ماشین و سایر پروژههای باحال، صحبت خواهم کرد. امیدوارم که این مطلب مفید فایده واقع شده باشه و وقتی که براش گذاشتید ارزشش رو داشته باشه.
خیلی از افرادی که این روزها، میخوان پروژههایی در حوزههای مختلف هوش مصنوعی مثل یادگیری ماشین، یادگیری عمیق، علوم داده و … انجام بدن یک گلوگاه بسیار بزرگ دارند و اون «داده» است. خیلیها واقعا نمیدونن از کجا میتونن دادههای مناسب پروژههاشون به دست بیارن. در این مطلب، قراره که این موضوع رو پوشش بدم.
منابع مناسب داده برای پروژههای شما
در این بخش، با هم چندین منبع مناسب برای پیدا کردن داده رو بررسی خواهیم کرد. فقط قبل از هرچیز این رو بگم که این منابع میتونن تغییر کنن در طول زمان پس هرچه که در این مطلب بیان شده رو در مرداد ۱۴۰۰ معتبر بدونید و اگر مدتی بعد از انتشار این مطلب دارید مطالعهش میکنید، با جستوجو و پرسوجو در مورد این منابع، اطلاعات بهروزتر دریافت کنید.
Kaggle
وبسایت کگل، یک محیط تقریبا مشابه شبکههای اجتماعی برای دانشمندان داده و متخصصین هوش مصنوعی به حساب میاد. در این وبسایت شما میتونید مجموعه داده (Dataset) های خوبی رو پیدا کنید. همچنین، میتونید کارهایی که ملت روی اون دادهها انجام دادن رو در قالب Kaggle Kernel (به نوعی همون جوپیتر نوتبوک خودمون) ببینید و یا کارهای خودتون هم به اشتراک بذارید.
برای دسترسی به کگل، میتونید روی این لینک کلیک کنید.
Academic Torrents
این وبسایت هم وبسایت جالبیه (و به نوعی مرتبط با بخش بعدی). در واقع هر حرکت آکادمیکی که زده شده و اطلاعاتش هم همزمان منتشر کردند رو در خودش داره. چرا؟ چون جست و جو در محتوای آکادمیک نسبتا سخته و این وبسایت اون کار رو براتون راحت کرده. همچنین یک بخش خوبی برای مجموعهداده (لینک) هم در این وبسایت در نظر گرفته شده.
برای دسترسی به این وبسایت، میتونید از طریق این لینک اقدام کنید.
وبسایت دانشگاهها
همونطوری که در بخش قبلی گفتم، بسیاری از دانشگاهها (و در کل، فضاهای آکادمیک) تحقیقات زیادی انجام میدن و دادههای اون تحقیقات رو هم معمولا منتشر میکنن. چرا که یکی از اصول مطالعات آماری، اینه که دادهها به صورت شفاف منتشر بشن (شاید دلیلش اینه که بعدها، یکی بخواد خودش اون آزمایش و مطالعه رو تکرار کنه و …).
به همین خاطر، وبسایت دانشگاهها – چه ایرانی و چه خارجی – میتونه محل خوبی باشه برای مراجعه و پیدا کردن دادههای خوب برای مطالعه.
دیتاستهای متنباز شرکتها
بسیاری از شرکتهای بزرگ مثل گوگل، فیسبوک، آمازون و …، میان و حجم خوبی از دادههایی که قبلتر در تحقیقاتشون استفاده کردند رو به صورت اوپنسورس، منتشر میکنن. پیدا کردن این دیتاستها هم اصلا کار سختی نیست.
برای مثال، در این لینک میتونید دیتاستهای گوگل رو ببینید. یکی از نمونههایی که خود گوگل اینجا مطرح کرده، دیتاست مرتبط با بیماری کووید-۱۹ است. (لینک)
چرا این شرکتها، دیتاستها رو منتشر میکنن؟ باز هم میگم دقیقا به همون دلیلی که دانشگاهها منتشر میکنن. شاید افراد یا سازمانهایی باشن که بخوان تحقیقات و مطالعات رو برای خودشون تکرار کنند و یا نتیجه آزمایشات و … رو صحتسنجی کنند.
خزیدن (Crawling) صفحات وب
خب، بعضی وقتا هم دادهای که ما نیاز داریم، توسط شرکتها یا دانشگاهها منتشر نشده. پس در این حالت چه کار میکنیم؟ اگر داده مورد نظر، در اینترنت موجود باشه، میتونیم یک خزنده (Crawler) بسازیم و با اون کارمون رو پیش ببریم.
در بسیاری از زبانهای برنامهنویسی و چارچوبهاشون، ابزارهای بسیار خوبی برای کراول کردن صفحات وب وجود داره. یکی از بهترین نمونههاش میتونه BeautifulSoup در پایتون باشه. در مطالب بعدی، احتمالا با استفاده از این ابزار، یک خزنده برای وبسایتهای مختلف خواهیم نوشت.
دوربین، میکروفن، حرکت!
اگر دادههای مورد نیاز ما حتی به شکلی که بتونیم کراول کنیم موجود نبود چی؟ سادهست. ابزارهای ورودی خوبی برای کامپیوتر وجود داره که میتونه بهمون کمک کنه تا داده مورد نظر رو جمعآوری کنید.
گذشته از این، دوربین تلفنهای همراه، میتونه منبع خوبی باشه برای جمع آوری تصاویر(پروژههای بینایی ماشین و …)، میکروفنهای استودیویی برای دریافت صدا خوبن. اگر نیاز به دیتایی مثل گرما یا رطوبت نیاز دارید، طراحی مداری که این داده رو از محیط بخونه و روی دیتابیس خاصی ذخیره کنه کار سختی نیست.
جمعبندی
پروژههای هوش مصنوعی به ذات سخت نیستند. چیزی که اونها رو سخت میکنه، همین دیتای ورودی و تمیزکاری و مرتب کردنشه. بعضی وقتا دادههای ما کم هستند و ما مجبور خواهیم شد که Data augmentation انجام بدیم. بعضی وقتا ممکنه نویز به قدری زیاد باشه که اصلا مرحله جمعآوری دیتا رو مجبور بشیم دوباره از نو انجام بدیم و … .
خلاصه هدف از این مطلب این بود که اگر پا در این عرصه گذاشتید، بدونید همیشه جایی هست که بتونید بدون مشکل، دادههایی رو دریافت و در پروژهتون استفاده کنید و از بابت نویز و …، خیالتون تا حد خوبی راحت باشه.
پس از مدت طولانی، با یک پست دیگر برگشتم و این بار قراره با هم احراز هویت JWT رو در ریلز بررسی کنیم. اول از همه، لازمه بدونیم JWT چیه؟ چرا نیازش داریم؟ اصلا چرا احراز هویت و هزاران چرای دیگر که احتمالا الان در سر شما هستند. بعدش یک پروژه خیلی کوچولو ایجاد میکنیم و با هم براش احراز هویت رو پیادهسازی میکنیم 🙂
احراز هویت JWT چیه و چرا بهش نیاز داریم؟
اول از همه این سوال بنیادیتر رو پاسخ بدیم که «چرا احراز هویت نیاز داریم؟» و بعد بریم سراغ احراز هویت JWT که قراره در این مطلب در موردش مفصل حرف بزنیم.
ما به احراز هویت نیاز داریم چون همیشه بخشی از دادههای ما، خصوصی هستند. گذشته از اون، احراز هویت میتونه اجازه CRUD رو به شما بده، نه؟ فکر کنید اپی دارید که هرکسی میتونه روش بخونه و بنویسه. ممکنه خوندن چیزی باشه که برای «همه» مناسب باشه اما «نوشتن» اینطور نیست. بخصوص که نوشتن خودش به قسمتهایی مثل حذف و بروزرسانی هم شکسته شده.
پس ما به احراز هویت نیاز داریم که هر ننهقمری (😂) نتونه از API ما استفاده کنه. بلکه کاربرانی که ثبتنام کردند و دسترسی درستی به سرویس دارند، بتونن استفاده کنن. این قضیه در API های تجاری (یا Business facing) خودشون رو بیشتر و بهتر نشون میدن.
حالا سوال مهمتر …
احراز هویت JWT چیه؟
در اپهای قدیمی (مثل همین وردپرس)، احراز هویت توسط cookie ها انجام میشه. به چه صورتی؟ به این صورت که وقتی نام کاربری و گذرواژه وارد میکنیم، نرمافزار فضایی رو در مرورگر به خودش اختصاص میده و یک سری اطلاعات رو با خودش جابجا میکنه. اما در ReST API ها این قضیه رو نداریم. در واقع نمیتونیم به کوکیها اعتماد کنیم. پس چه میکنیم؟ اینجا لازمه جز یوزرنیم(که معمولا میتونه عمومی باشه) و پسورد (که میتونه راحت لو بره) میاییم و یک «توکن» هم تعریف میکنیم. این توکن، میتونه ثابت یا متغیر باشه. یعنی چی؟ یعنی میتونه به ازای هربار ورود تغییر کنه، میتونه سر زمان مشخصی هم منقضی بشه.
حالا توکن چیه؟ توکن به صورت کلی، در کازینوها معادل پولیه که شما در بازیها قرار میدید، در واقع مجوز حضور شما در اون کازینو، کلاب و … است. حتی به رمزارزهایی که بر مبنای دیگر رمزارزها ساخته میشن هم سکه نمیگن بلکه میگن توکن. شما فرض کنید که مثلا ۱۰۰ دلار میدید و پنج تا سکه با آرم اون کازینوی خاص دریافت میکنید. اگر در بازی برنده بشید یا ببازید، باید توکنهاتون رو تحویل بدید یا بگیرید.
حالا در احراز هویت JWT هم، ما به ازای کاربرمون یک توکن در نظر میگیریم. این توکن، معمولا یک رشته طولانیه که انسان نمیتونه بخوندش. نتیجتا خیلی از اطلاعات ما به صورت ایمنتر میتونن رد و بدل بشن (طبیعیه که مواردی مثل SSL داشتن و الگوریتمهایی که در ساخت توکن داشتیم هم مهمن). ضمن این که نامکاربری، ایمیل، رمزعبور و .. هم به همین سادگیا نمیتونن خونده بشن.
پس ما میآییم و یک دیتابیسی از توکنها در کنار دیتابیسی از یوزرها میسازیم (البته درستترش، جدوله!) و به ازای هر یوزر معمولا دوتا توکن در اون دیتابیس قرار میدیم. یکیش رو بهش میگیم «توکن دسترسی» یا Access Token و یکی رو میگیم «توکن بازنشانی» یا Refresh Token. توکن دسترسی، معمولا یک تاریخ انقضایی داره و بعد از اون با استفاده از توکن بازنشانی، میتونیم یکی جدید بگیریم. اما در آموزش امروز، صرفا میخوایم توکن دسترسی رو به دست بیاریم.
احراز هویت JWT به این شکل کار میکنه
خب، الان که تقریبا همهچی رو میدونیم، بریم برای پیادهسازی.
پیادهسازی یک اپلیکیشن ریلز با JWT
خب در قدم اول، باید یک اپ ایجاد کنیم. این اپ رو به این شکل ایجاد میکنیم:
rails new devise-jwt --api
خب توضیح واضحات:
قسمت rails که واضحا فراخوانی نرمافزار rails در ترمینال ماست.
قسمت new در خواست برای ایجاد یک اپ جدیده.
قسمت devise-jwt اسم پروژه ماست. حالا چرا؟ چون قراره از یک لایبرری با همین اسم استفاده کنیم. بنابراین، پروژه رو اینطوری اسم گذاشتیم.
در قسمت آخر هم، به ریلز گفتیم که ما تو رو بخاطر API هات دوست داریم. ویو نیاز نیست.
بعد از چند ثانیه (و بسته به سرعت اینترنت دقیقه) اپ ما ساخته میشه. بعد لازمه که مرحله مرحله کارهایی رو انجام بدیم.
نصب لایبرریهای مورد نیاز
خب، اول از همه با ویرایشگر متنی مورد علاقمون فایل Gemfile رو باز میکنیم و این خطوط رو بهش اضافه میکنیم :
gem 'devise'
gem 'devise-jwt'
gem 'rack-cors'
بعد از این که این خطوط رو اضافه کردیم، دستور زیر رو اجرا میکنیم:
bundle
این دستور چه کار میکنه؟ میاد و تمام لایبرریهای مورد نظر شما رو به صورت ایزوله در یک دایرکتوری، نصب میکنه. به این شکل شما میتونید به سادگی بدون رسیدن آسیب به باقی لایبرریهای روبی نصب شده روی سرور یا حتی کامپیوتر خودتون، ایدههاتون رو تست کنید.
لازم به ذکره که بعد از اجرای این دستور فایل Gemfile.lock بهروز میشه، این فایل حالا چه کار میکنه؟ این فایل حواسش به همهچی هست. در واقع، ورژن روبی، ورژن ریلز، لایبرریهای مورد نیاز و ورژنینگشون و … رو همه رو این فایل داره کنترل میکنه.
بعد از انجام مراحل فوق، کافیه این دستور هم اجرا کنیم:
rails g devise:install
این دستور چه میکنه؟ این دستور هم برای ما فایلهای devise رو در جای درستش قرار میده.
آشنایی با devise
برای احراز هویت در هر سیستمی ما دو راه داریم:
نوشتن سیستم احراز هویت از بیخ
استفاده از کتابخانههای موجود
در مورد روش «از بیخ»، ما معمولا این کار رو انجام نمیدیم. چرا؟ چون معمولا اونقدر خوب نیستیم که بتونیم امنیت سیستم رو به خوبی تامین کنیم. در مورد دوم، در هر فرمورک و زبانی، کتابخانههایی ساخته شدند که کمک میکنن ما بتونیم با اضافه کردنشون به پروژه خودمون، بخش احراز هویت رو هندل کنیم. برای ریلز devise ساخته شده. این لایبرری، یک لایبرری مبتنی بر cookie برای احراز هویت وباپهاست.
بعد از همهگیر شدن ReST API ها، لایبرری devise-jwt هم نوشته شد. این لایبرری، ابزاریه که به من و شما کمک میکنه بتونیم احراز هویت JWT رو به پروژهمون اضافه کنیم. در واقع هر سه لایبرری که به پروژه اضافه کردیم، کارشون همینه که JWT رو برای ما راحت کنند.
هندل کردن CORS
در این مطلب قصد ندارم در مورد CORS حرف بزنم، چون قبلتر ازش حرف زدم (و میتونید اینجا بخونید). اینجا ما صرفا قصدمون اینه که بیاییم و این مشکل رو حل کنیم. چطوری؟ خب این فایل:
config/initializers/cors.rb
رو با ویرایشگر متنی مورد علاقهمون باز میکنیم، و محتواش رو به این شکل تغییر میدیم:
Rails.application.config.middleware.insert_before 0, Rack::Cors do
allow do
origins '*'
resource '*',
headers: :any,
methods: [:get, :post, :put, :patch, :delete, :options, :head]
end
end
توجه کنید که این قسمت معمولا به صورت کامنتشده در کد هست، فقط کافیه آنکامنتش کنید و نیاز نیست که کلا این مورد رو کپی پیست کنید.
ساخت مدل و کنترلرهای مورد نیاز برای کاربر
یکی از خوبیهای devise اینه که به شکل scaffold گونهای، میتونه به ما کمک کنه که کاربر و سیستم کنترلش رو بسازیم. برای ساخت مدل کاربر فقط کافیه که این دستور رو اجرا کنیم:
rails g devise User
به این شکل میفهمه که باید یک مدل، مطابق مدل User ولی با مشخصات devise برامون بسازه. بعدش هم کافیه این دستور رو اجرا کنیم:
rails db:migrate
که جدولای مرتبط برامون در دیتابیس ساخته بشن.
حالا که خیالمون از بابت این قضایا راحت شد چی؟ هیچی. دو تا کنترلر هم میسازیم به این شکل:
rails g controller users/sessions
rails g controller users/registrations
بعد از این میشه گفت که کار ما اینجا تمام شده و باید بریم یه چیزایی رو ادیت کنیم 🙂
ویرایش مدل یوزر
بعد از این که کارهای بالا رو انجام دادیم، کافیه که بریم سراغ مدل یوزرمون و به این شکل ادیتش کنیم:
class User < ApplicationRecord
devise :database_authenticatable,
:jwt_authenticatable,
:registerable,
jwt_revocation_strategy: JwtDenylist
end
حالا این کار برای چیه؟ برای اینه که ما یک جدول دیگر به اسم JWT Deny List در نظر میگیریم و توکنهای منقضیشده رو درونش قرار میدیم. به اون شکل وقتی توکنی منقضی بشه، میتونیم به کاربر خطا نشون بدیم یا از توسعهدهندههای فرانت تیم بخوایم که وقتی اون خطا رو دیدن، کاربر رو لاگ اوت کنن. خلاصه که راه برای رسیدن به نتیجه مطلوب زیاده. بگذریم، بعد از این، در پوشه مدلها لازمه که یک فایل به اسم jwt_denylist.rb ایجاد کنیم و این محتوا رو درونش قرار بدیم:
class JwtDenylist < ApplicationRecord
include Devise::JWT::RevocationStrategies::Denylist
self.table_name = 'jwt_denylist'
end
بعد نیاز داریم که برای این قضیه یک مایگرشن اضافه کنیم:
rails g migration CreateJwtDenylist
سپس، فایل مایگرشن که معمولا در آدرس:
db/migrate
قرار داره رو باز میکنیم و محتواش رو به این شکل تغییر میدیم:
class CreateJwtDenylist < ActiveRecord::Migration[6.1]
def change
create_table :jwt_denylist do |t|
t.string :jti, null: false
t.datetime :exp, null: false
end
add_index :jwt_denylist, :jti
end
end
و بعد یک دور مایگرشنها رو اجرا میکنیم:
rails db:migrate
تا اینجا مطلب طولانی شد؟ ایرادی نداره. بریم یک قهوه بزنیم به بدن و برگردیم 🙂
کنترلر Session
امیدوارم که کافئین به قدر کافی مودتون رو بالا آورده باشه 🙂 حالا وقتشه که بریم و کنترلر session رو درست کنیم. نیازی نیست واقعا کار خاصی کنیم. تنها کاری که نیازه بکنیم اینه که کنترلری که ساختیم رو باز کنیم و این موارد رو درش کپی کنیم:
class Users::SessionsController < Devise::SessionsController
respond_to :json
private
def respond_with(resource, _opts = {})
render json: { message: 'You are logged in.' }, status: :ok
end
def respond_to_on_destroy
log_out_success && return if current_user
log_out_failure
end
def log_out_success
render json: { message: "You are logged out." }, status: :ok
end
def log_out_failure
render json: { message: "Hmm nothing happened."}, status: :unauthorized
end
end
نکته مهم، اگر هنگام ساخت کنترلر، جای users از چیز دیگری استفاده کردید باید Users رو در کد بالا به اون تغییر بدید. اگر هم کلا چیزی نذاشتید، کل قسمت Users:: رو ازش حذف کنید.
کنترلر Registration
خب عین همون بخش قبلی، شما کافیه کنترلر registrations رو باز کنید و این کد رو درونش کپی کنید:
class Users::RegistrationsController < Devise::RegistrationsController
respond_to :json
private
def respond_with(resource, _opts = {})
register_success && return if resource.persisted?
register_failed
end
def register_success
render json: { message: 'Signed up sucessfully.' }
end
def register_failed
render json: { message: "Something went wrong." }
end
end
تنظیمات نهایی devise
خب اول در ترمینال (یا cmd) این دستور رو اجرا کنید:
rake secret
و یک کد طولانی و مسخره بهتون میده 😁 اون رو در فایل:
config/initializers/devise.rb
در آخر فایل به این شکل کپی کنید:
config.jwt do |jwt|
jwt.secret = rake_secret_output
end
نکته بسیار مهم اینجا چیه؟ این که حواستون باشه این صرفا یک پروژه تسته و برای محیط پروداکشن اصلا جالب نیست که سیکرتها و توکنها، هاردکد باشن. برای اون زمان میتونید از ENV استفاده کنید.
مسیرها
خب، الان که تقریبا همهچی آرومه و ما چقدر خوشحالیم، کافیه که بیاییم و فایل routes.rb رو هم به این شکل ویرایش کنیم:
Rails.application.routes.draw do
devise_for :users,
controllers: {
sessions: 'users/sessions',
registrations: 'users/registrations'
}
end
خب پس چی میمونه که انجام ندادیم؟ یک سری آزمایش ساده 🙂
ساخت کاربر
خب الان کافیه بعد اجرای سرور ریلز (مطابق آموزشهای قبلی)، این دستور رو اجرا کنیم:
که اینها سرایند (Header) های ما هستند. در این قسمت، هرچی جلوی Authorization قرار داره توکن ماست. و میتونیم ازش استفاده کنیم.
بخش بعدی هم اینه :
{"message":"You are logged in."}
که صرفا به ما میگه ورودمون موفقیتآمیز بوده.
فکر کنم این مطلب، آخرین مطلبی بود که در مورد بیسیکهای روبیآنریلز مینوشتم. احتمالا در آینده نهچندان دور، همه اینها رو با هم به یک سری آموزش ویدئویی تبدیل کنم و از طریق آپارات یا یوتوب منتشرشون کنم.
طبیعتا یک قسمتهایی از آموزش در این مطلب پوشش داده نشده، سعی میکنم در آینده یک یا دو پست تکمیلی هم ارائه کنم که همه این قضایا به خوبی پوشش داده بشه (یا این که کلا در بخش ویدئویی در خدمتتون باشم).
به صورت کلی، دوست دارم بدونم نظر شما در مورد این تیپ آموزشها چیه؟ آیا ادامهشون بدم یا خیر؟ و این که آیا پایهش هستید که بحث فرانتند رو هم شروع کنیم یا روی همین بکند باقی بمونیم و اول یه پروژه کامل رو بکندش رو بزنیم و بعد بریم سراغ فرانت؟ 🙂
در آخر هم بابت وقتی که گذاشتید و مطلب رو خوندید ازتون متشکرم.
در پست قبلی با هم یک REST API نوشتیم که یک نمونه از مدل «پست» رو میتونست ایجاد کنه، بروز کنه، نمایش بده و نابود کنه.
در این پست هم قصد دارم که کار مشابهی کنم، منتها این بار تیم محصول به ما یک سناریوی جدید داده. از ما خواستند که این بار، کامنت هم به پستها اضافه کنیم و بتونیم با استفاده از API برای هرپستی، یک کامنت هم ایجاد کنیم. پس وقت رو غنیمت میشماریم و میریم سروقت پروژه (پوشهها و ساختار عینا مثل پست قبلیه و هیچ تغییری در اون رخ نداده).
ساخت مدل برای کامنت
بیاییم ببینیم تیم محصول برای ما چی طراحی کرده. این عزیزان در نظر دارند که هر کامنت صرفا یک «متن بدنه» داشته باشه و بیشتر از اون نیاز نداشتند. کار ما اینه که حالا مدلی طراحی کنیم که علاوه بر اون، به پستها هم ربط داشتهباشه. چطوری این کار رو میتونیم بکنیم؟
کافیه دستور زیر رو اجرا کنیم و مدلش رو بسازیم:
rails generate model Comment body:text post_id:integer
خب حالا میریم به پوشه :
app/models
و اول post.rb رو به این شکل ویرایش میکنیم:
class Post < ApplicationRecord
has_many :comments
end
و سپس comment.rb رو به این شکل ویرایش میکنیم:
class Comment < ApplicationRecord
belongs_to :post
end
حالا این خطوط چی میگن؟ ما در پایگاه داده چندین نوع رابطه داریم. توضیح این روابط به صورت مفصل باشه برای یک پست دیگه. اما اینجا بیاید در نظر بگیرید که طراحی محصول به شکلی بوده که «هر پست میتونه بیشمار کامنت داشته باشه و هر کامنت متعلق به فقط و تنها فقط یک پسته». این نوع رابطه اسمش هست «یک به چند» یا بهتر بگم «یک به خیلی» و به قول خارجیها One to many.
حالا که از این قضیه خبر داریم و پست رو هم ساختیم تعلل نمیکنیم. میریم سراغ ساخت کنترلر مربوطه. اینجا کنترلر به ما کمک میکنه که بتونیم به سادگی یک کامنت رو روی پست بسازیم و مدیریت کنیم. در مورد سناریوی کنترل کامنت هم این بار کمی سادهتر میگیریم. در ادامه این مورد رو با هم بررسی خواهیم کرد.
ساخت کنترلر کامنت
اول کنترلر کامنت رو به این شکل ایجاد میکنیم:
rails generate controller api/v1/comments
و سپس در فایل:
config/routes.rb
این تغییر ریز رو ایجاد میکنیم :
Rails.application.routes.draw do
namespace :api do
namespace :v1 do
resources :post do
resources :comments
end
end
end
# For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html
end
و بعد میریم سروقت کنترلر 🙂 اما قبل از اون بیاید یه چیزی رو بررسی کنیم. این روابط رو! این روابط چطوری تعیین شدند؟ و چرا مهمند. پس در ترمینالمون تایپ میکنیم:
rails c
این دستور، به ما یک «کنسول ریلز» میده. کنسول به ما کمک میکنه که ایدهها رو در یک لول قبل از مرورگر و درخواستهای HTTP بررسی کنیم. در اسکرینشات زیر از ترمینال من، میبینید که چطوری یکی از پستها رو تست کردم و دیدم که آیا روابطش با کامنتها درسته یا خیر.
خب حالا بیاییم کنترلر رو بنویسیم. قبل از اون، من یک کامنت دستی در کنسول به این شکل میسازم:
c = Comment.new(:body => "This is a comment", :post_id => 1)
c.save
و کنسول رو میبندم. میریم سراغ کنترلرمون. همونطور که گفتم اینجا یه سری چیزا نیستن. مثلا show اینجا نیازی نیست باشه ولی index نیاز هست. پس میریم سراغ این که این موارد رو در کنترلر لحاظ کنیم. خب با توجه به این توضیحات، ما یک متد index به این شکل نیاز داریم:
def index
@post = Post.find(params[:post_id])
render json: @post.comments
end
همونطور که دیدید، اینجا تنها چیزی که نیازه بررسی بشه post_id ماست. درخواستی که به سمت سرور میفرستیم هم به این شکله:
curl -X GET -i http://localhost:3000/api/v1/post/1/comments
حالا وقتشه که بتونیم یک کامنت جدید ایجاد کنیم. برای ساخت کامنت جدید هم کافیه که به این شکل، متد create رو بنویسیم:
def create
@comment = Comment.new(:body => params[:comment][:body], :post_id => params[:post_id])
if @comment.save
render json: {:status => "success", :comment => @comment}
end
end
و نمونه درخواستی که براش میفرستیم هم به این شکل:
curl -X POST -H 'Content-Type: application/json' -i http://localhost:3000/api/v1/post/1/comments --data '{
"body":"This is another comment"
}'
حالا یک سوال مهم ممکنه برای شما پیش بیاد و اون هم اینه که :
چرا پارامترهای ارسالی فرق دارند؟
دلیلش خیلی سادهست. ریلز اول میاد پارامترهای درون URL رو مستقیم میخونه، بعد میاد سراغ Request Body که در واقع اگر سلسله مراتبی (مثل یک فایل YAML) بهش نگاه کنیم این شکلی میشه:
- post_id: 1
- comment:
- body: "This is another comment"
در واقع برای خودش یک Resource space در نظر میگیره و body رو از اون میخونه. به همین خاطره که یکی زیرمجموعه comment و دیگری مستقیما post_id میشه.
باقی متدها چی؟
معمولا کامنتها قابل ادیت و حذف و … نیستند. ما هم به جهت سادگی این ماجرا رو براشون پیادهسازی نمیکنیم تا بعدا چه پیش آید 🙂
جمعبندی دو قسمت اخیر
خب در این دوقسمت ما خیلی چیزا یاد گرفتیم که فهرستوار بررسی میکنیم :
چطور ریلز نصب کنیم.
چطور یک پروژه ریلز جدید ایجاد کنیم.
چطور یک منطق تجاری (Business Logic) رو درک کنیم
چطور مدلهای مورد نظر رو بسازیم
چطور API بسازیم و تست کنیم.
این موارد بسیار مهمن و فکر کنم بعد خوندن این دو قسمت حداقلهای ساخت یک API رو یاد گرفتید. بعد از این چه چیزهایی لازمه که یاد بگیریم؟ این دیگه بستگی به خودتون داره. شاید در موردش مطلبی بنویسم اما فکر کنم این آخرین مطلبیه که انقدر مستقیم داره به نوشتن و ساختن API اشاره میکنه.
در مطالب بعدی، میخواهیم بریم سراغ یک سری مفهوم و پیادهسازی دیگر. احتمال قوی هم بریم سراغ فرانتند و ببینیم که در دنیای فرانتند چه خبره. پس منتظر باشید که فصل جدیدی از مطالب فنی در راهه 🙂
در آخر، از شما بابت وقتی که برای خوندن این مطلب گذاشتید هم کمال تشکر رو دارم.
پس از مدتی دست کشیدن از بلاگ نوشتن، به دنیای نویسندگی فنی برگشتم و قراره که امروز با هم یاد بگیریم چطور یک Rest API رو با روبی آن ریلز بسازیم. چرا روبی آن ریلز؟ دو تا دلیل داره. یکی این که چون من بلدمش و دلیل دوم این که منبع فارسی خوب براش به شدت کمه (کما این که برنامهنویس خوب ریلز کم نداریم در ایران).
در این پست قراره چیا یاد بگیریم؟ اول این که Rest چیه. بعدش با ریلز یه پروژه جدید ایجاد میکنیم، بعدش هم یک سناریوی ریزی که در این قسمت تا بخش خوبیش رو پیش میبریم. در قسمت بعدی هم پروژه رو تموم میکنیم و میریم که داشته باشیم فرانتند رو 🙂
تعریف Rest
واژه REST مخفف Representational State Transfer و به معنای «انتقال بازنمودی حالت» است. یعنی چی؟ یعنی ساده و مختصر و مفیدش اینه که شما هرچی که دارید رو بدون تغییر در حالاتش، به کاربر منتقل میکنید. یک تعریف بهترش هم اینه که همه چی به شکل یک لینک اینترنتی و خروجی قابل فهم برای مرورگر (و البته بهتر بگم، پروتکل HTTP) دربیاد.
رست، مزایای خاص خودش هم داره. اما بزرگترین مزیتش اینه که همهجا یکیه! یعنی اینطوری نیست که روی وبسایت من یه شکل باشه و روی یک وبسایت دیگه یه شکل دیگه. همهجا میتونید با دانشی که از HTTP و ابزارهایی که برای ارسال و دریافت درخواست HTTP دارید، باهاش کار کنید. ابزاری که در این پست باهاش کار میکنیم چیزی نیست جز curl دوست داشتنی. یک ابزار خطفرمانی در یونیکس که سالیان ساله برای هر بده بستانی با HTTP داره استفاده میشه.
نصب و راهاندازی روبی، ریلز و نود جی اس!
نصب کردن این موارد حقیقتا چیزی نیست که بخوام در این مطلب بهشون اشاره کنم، فقط یک سرنخ کوتاه میدم و شما خودتون دنبالش کنید.
همونطور که از اسم فرمورک مورد نظر پیداست، یک چارچوب توسعه روی زبان روبی محسوب میشه. حالا چطوری روبی رو نصب کنیم؟ یک راه نسبتا بدی هست که از مخازن توزیع یا brew نصب کنیم، یک راه بهتر هم استفاده از RVM میتونه باشه. شخصا همیشه از RVM استفاده میکنم، و راضی هم هستم. چون بهتون اجازه میده که چندین و چند نسخه روبی نصب داشته باشید.
برای نصب RVM از وبسایتش (لینک) استفاده کنید. این ابزار روی لینوکس و مک به راحتی نصب میشه. برای نصب روی ویندوز هم من از همین ابزار به کمک WSL استفاده کرده بودم و نتیجه، رضایت بخش بود. بعد از نصب این بزرگوار مطابق راهنماهاش، یک نسخه روبی (پیشنهاد من ۲.۷.۲ که این مطلب با استناد به استانداردهاش نوشته شده) نصب کنید. بعد از نصب روبی، این دو دستور رو اجرا کنید که ریلز و متعلقات نصب بشن:
gem install bundle
gem install rails
نصب ریلز یکمی طولانیه. میتونید این زمان رو صرف نوشیدن یک فنجان قهوه کنید 🙂 این طولانی بودن هم ربط زیادی به اینترنت نداره، چون روی بستههای خاصی مثل sass یکم درجا میزنه چون نیاز داره یه چیزایی رو کامپایل کنه.
بعد از این، شما با مراجعه به وبسایت نود جی اس (لینک) و yarn (لینک) میتونید اینها رو هم متناسب با سیستمعامل خودتون نصب کنید. حالا همه چی آمادهست که پروژهمون رو بزنیم 🙂
آغاز پروژه
سناریو
خب بیاید فرض کنیم که یک شرکتی قراره یه سرویس وبلاگدهی مشابه مدیوم یا ویرگول ارائه کنه. در حال حاضر هیچی ازمون نخواسته جز :
امکان ارسال پست از طریق API
امکان ارسال نظر روی پست از طریق API
و خب در حال حاضر احراز هویت و … براشون مهم نیست چون میخوان ببینن که MVP کار میکنه یا نه؟! و ما هم از خداخواسته قبول کردیم این رو براشون پیاده کنیم. اما این همه ماجرا نیست. این دو مورد، باید یک سری ویژگی هم داشته باشن. این ویژگیها رو طراح محصول باید درآورده باشه. فرض کنیم که طراح محصول اینا رو درآورده و فعلا برای «پست» به ما یک سری ویژگی داده :
عنوان یا title : یک رشته کرکتری
عنوان کوتاه یا slug : یک رشته کرکتری که با – از هم جدا میشه، یک رشته رندم هم تهش میچسبه که منحصر به فرد بودنش رو تعیین کنه (چسبیدن رشته رندم رو از فرانت هندل کنید)
بدنه یا body : متن اصلی.
خب، با این ویژگیها از ما میخوان که پست رو پیاده کنیم تا ویژگیهای کامنت رو بهمون بدن 🙂
ساخت پروژه جدید
ساخت پروژه جدید در ریلز بسیار سادهست. شما فقط کافیه که در پوشهای (مثلا من روی کامپیوتر یه پوشه دارم به اسم playground که پروژههای شخصیم توشن) که میخواید پروژه اونجا باشه، این دستور رو اجرا کنید:
rails new api-tutorial --api
اینجا چی کار میکنیم؟ rails که مشخصه، داره rails رو فراخوانی میکنه. new میگه یک پروژه جدید میخوام. قسمت بعدی، اسم پروژه و طبیعتا اسم پوشه پروژهست. در نهایت بخش مهم همون api عه. این داره به ریلز میگه که viewها و کلا مسخرهبازیای فرانتی رو بعدا و جدا انجام میدم. فعلا مسخرهبازی بکندی میخوام فقط 😁
حالا با اجرای دستور زیر، میریم به داخل پوشه پروژهمون:
cd api-tutorial
ساخت مدل جدید برای پست
همونطور که از مطلب MVC (لینک) میدونیم، مدل تعیین میکنه که یک موجودیت در دیتابیس به چه شکل قرار بگیره. خب، الان کاری که ما باید بکنیم چیه؟ اینه که دستور زیر رو اجرا کنیم و بگیم که چی میخوایم:
rails generate model Post title:string slug:string body:text
خب، در اینجا دقیقا همون چیزی که طراح محصول خواسته رو داریم پیادهسازی میکنیم. خب، الان در پوشه:
app/models
یک فایل به اسم post.rb ساخته شده که توش تقریبا هیچی نیست. و فعلا به اون فایل، کاری نداریم (تو قسمت دوم در مورد این فایل صحبت خواهیم کرد).
الان فقط لازمه که به دیتابیس بفهمونیم که ما یک جدول جدید برای پستها نیاز داریم. برای اون کار، دستور زیر رو اجرا میکنیم:
rails db:migrate
این کار برای ما جدول و روابطش رو میسازه.
ساخت کنترلر برای پست
خب، ما نیاز داریم که عملیات CRUD روی پست انجام بدیم. چرا؟
هر پست نیاز داره ایجاد بشه. پستی که ایجاد نشه پستیه که قطعا ایجاد نشده 😐
هر پست نیازمند اینه که به کاربر نمایش داده شه. قرار نیست مخزنالاسرار بسازیم که!
هر پست نیاز داره که ویرایش بشه. فرض کنید یه جا تو پست نوشتیم «خورش کرفس بهترین غذای دنیاست». خب معلومه که باید «خورش کرفس» رو به «قرمه سبزی» تغییر بدیم.
و هر پست باید قابل حذف شدن باشه. در مورد حذف نرم و سخت بعدا صحبت خواهیم کرد. اما فرض رو روی destroy یا همون «حذف سخت» میذاریم. چون طراح محصول هنوز اطلاعات بیشتری بهمون نداده.
خب، الان که این رو یاد گرفتیم چی کار میکنیم؟ این دستور رو اجرا میکنیم:
rails generate controller api/v1/post index show create update destroy
بعدش فایل :
app/controllers/api/v1/post_controller.rb
رو باز کنید. با چنین صحنهای روبرو خواهید شد:
class Api::V1::PostController < ApplicationController
def index
end
def show
end
def create
end
def update
end
def destroy
end
end
خب اول از new شروع میکنیم! از حرف C ! اما قبلش باید یک تغییر کوچکی در این فایل بدیم :
class Api::V1::PostController < ApplicationController
def index
end
def show
end
def new
end
def update
end
def destroy
end
private
def post_params
params.require(:post).permit(:title, :slug, :body)
end
end
متد post_params چی کار میکنه؟ این متد میاد فقط مواردی که نیازن رو validate میکنه و نمیذاره پارامتر بیشتر و یا اشتباهی به endpoint مربوطه پاس بدیم. خب، الان متد new رو به این شکل تغییر میدیم:
def new
@post = Post.new(post_params)
if @post.save
render json: {:status => "success", :content => @post}
else
render error: {:status => "fail"}
end
end
خب یک مزیت دیگر استفاده از post_params هم همینه، بدون دردسر میتونیم همه پارامترها رو پاس بدیم به متدهامون. حالا، بهتر اینه که این متد رو تست هم بکنیم نه؟ پس این دستور رو وارد میکنیم:
rails server
این دستور، سرور ریلز رو ران میکنه و به ما اجازه میده که برنامه خودمون رو آزمایش کنیم.
اما الان بهمون ارور میده. پس چی کار کنیم؟ هیچی. این فایل :
config/routes.rb
رو باز میکنیم و به این شکل درش میاریم:
Rails.application.routes.draw do
namespace :api do
namespace :v1 do
resources :post
end
end
# For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html
end
و حالا دوباره تست میکنیم. چطوری؟ به این شکل:
curl -X POST -H 'Content-Type: application/json' -i http://localhost:3000/api/v1/post --data '{
"title":"Hello, World",
"slug":"hello-world-abcd1234",
"body":"Hello, world! this is a simple test for my app"
}'
و خروجیای که میده به این شکله:
{
"status": "success",
"content": {
"id": 1,
"title": "Hello, World",
"slug": "hello-world-abcd1234",
"body": "Hello, world! this is a simple test for my app",
"created_at": "2021-03-28T17:44:16.608Z",
"updated_at": "2021-03-28T17:44:16.608Z"
}
}
حالا وقتشه که بریم سراغ R یعنی Retrieve/Restore. یعنی نمایش پستها و پست به صورت تکی. کافیه index و show رو یکم دستخوش تغییر کنیم:
def index
@posts = Post.all
render json: @posts
end
def show
@post = Post.find(params[:id])
render json: @post
end
و الان با ارسال چنین دستوری:
curl -X GET -i http://localhost:3000/api/v1/post/1
میتونیم پستهامون رو ببینیم.
حالا بیایم برای ویرایش هم چارهای بیاندیشیم 🙂 پس متد آپدیت هم به این شکل بهروز میکنیم:
def update
@post = Post.find(params[:id])
if @post
@post.update(post_params)
end
end
خب، اینجا چرا else نگذاشتم؟ چون اگر پست موجود نباشه (موجودیتش با if چک میشه) خود ریلز به ما ارور مناسب (معمولا ۴۰۴) رو نشون میده.
من در سیستم خودم، یک پست با آیدی ۲ دارم که قرار بود آپدیت بشه. الان اون رو با این دستور آپدیت میکنم:
خب، در نهایت فایل post_controller.rb ما به این شکل در اومده:
class Api::V1::PostController < ApplicationController
def index
@posts = Post.all
render json: @posts
end
def show
@post = Post.find(params[:id])
render json: @post
end
def create
@post = Post.new(post_params)
if @post.save
render json: {:status => "success", :content => @post}
else
render error: {:status => "fail"}
end
end
def update
@post = Post.find(params[:id])
if @post
@post.update(post_params)
end
end
def destroy
@post = Post.find(params[:id])
if @post
@post.destroy
render json: {:status => "success", :post_id => @post.id }
end
end
private
def post_params
params.require(:post).permit(:title, :slug, :body)
end
end
کل چیزی که در این قسمت نوشتم، برای درک عملکرد API کافیه. از شما هم میخوام که همین سناریو رو برای خودتون، یک دور به صورت کاملا دستی پیاده کنید و سعی کنید درش خلاقیت به خرج بدید. تجربیاتتون هم در بخش نظرات با من به اشتراک بذارید 🙂
قسمت بعدی، چی یاد میگیریم؟
در قسمت بعدی، کاری میکنیم کارستان. یاد میگیریم که در مدلها روابطشون رو تعیین کنیم. بعد مدلی میسازیم که به این مدل وابستهست. در نهایت هم به همین شکل، کنترلرش رو میسازیم و پروژه رو تحویل کارفرمای عصبانی میدیم 🙂
از این که وقت گذاشتید و این پست رو خوندید، واقعا ممنونم. هر یک ویویی که این پستها میخوره، برای من شدیدا ارزشمنده.
در پست قبلی، بررسی کردیم که اصلا MVC چیه و به چه کار میاد و یکم هم مثال ازش در روبی آن ریلز دیدیم. در این پست، قصد دارم مزایا و معایبش رو بگم و بگم که روبی آن ریلز، چه راهحلی برای مشکلاتش پیشنهاد میکنه.
باز هم لازمه که سلب ادعا کنم که این مطلب مطلقا آموزش روبی آن ریلز نیست و شما اگر میخواید روبی آن ریلز یاد بگیرید، میتونید تا پست بعدی منتظر باشید 😁
مروری بر کلیت MVC
از پست قبلی، این دید رو داریم که MVC در واقع یک روش تبدیل کردن موجودیتهای محصول به یک سری مدل، کنترل ارتباطاتشون با هم و با دنیای بیرون با یک سری کنترلر و نمایششون به صورت ویوئه (متفاوتتر از قبلی شد، نه؟ چون صرفا بیانم رو در تعریفش عوض کردم). اما حرفی از مزایای و معایبش نزدم.
عمدهترین دلیلم برای ادامه ندادن، این بود که مطلب قبلی زمان زیادی از من گرفت و حتی مجبور به ریبوت کردن لپتاپم میانه راه شدم. خود مطلب هم شدیدا طولانی بود و مطمئن بودم از یک حدی طولانیتر میشد، دیگه کسی اون رو نمیخوند.
حالا که تعاریف رو با هم بررسی کردیم، بریم سراغ اصل مطلب 🙂
مزایا و معایب معماری MVC
مزایا
تسریع فرایند پیادهسازی : همونطوری که در پست قبلی دیدید، اکثریت قریب به اتفاق چارچوبهای توسعه که با این معماری کار میکنند، ابزارهایی برای تولید و تست موجودیتها در اختیار شما میذارن. این به خودی خود موجب تسریع فرایند پیادهسازی میشه. در مورد توسعه هم این قضیه میتونه تا حدی صادق باشه، البته توسعه رو در بخش معایب بررسی میکنیم.
تسهیل فرایند کار گروهی : در یک بیزنس، معمولا بیش از یک نیرو روی محصول نهایی – چه در پیادهسازی چه در توسعه – کار میکنه. این معماری به توسعهدهندهها کمک میکنه بهتر بتونن محصول رو درک کنن. بخصوص اگر قرار باشه هر شخص روی یه بخشی کار کنه و پیادهش کنه.
تسهیل فرایند بهروزرسانی : طبیعیه که بهروزرسانی یک محصول، کار سادهای نیست. اما یک فرض ساده رو در نظر بگیرید. مثلا من، یک فروشگاه اینترنتی دارم، قراره در نسخه جدید وبسایتم، بخشی هم افتتاح کنم که افراد بتونن لوازم کارکرده هم خرید و فروش کنن. اضافه کردن یک موجودیت جدید به نرمافزاری که MVC نوشته شده به شدت سادهتر میشه و من فقط لازمه مدل بخش «کارکرده» رو اضافه کنم و روابطش با باقی اجزا رو پیادهسازی کنم.
تسهیل فرایند کشف و رفع باگ : خب از اونجایی که هر موجودیتی، در این معماری به شکلی جدا از موجودیت دیگره، خیلی راحت میشه فهمید مشکل از کجاست. البته لازمه این رو بگم که در معایب هم قراره به این بخش اشاره کنیم و در گوشتون هم میگم که Rest API در این زمینه میتونه بهتر عمل کنه 🙂
خب ما ایرانیا یک ضربالمثل معروف داریم که میگه «گل بیعیب، خداست». پس این معماری و طبیعتا فرمورکهایی که با این معماری کار میکنند هم خالی از ایراد نیستند. در این بخش از معایب MVC میگم و البته بخشیش هم از معایبی که برای ریلز و لاراول گفته شده نقل میکنم.
در مورد بخشی که از ریلز و لاراوله، اسمی از فرمورک نمیارم چون در نظرم این معایب، معایب معماری هستند و نه فرمورک. در واقع اینطوری فرض کنیم که یک سلولی که مشکلی داشته تقسیم شده و همه سلولهای جدید، همون مشکل رو دارند 😁
معایب
سختی درک معماری : این موضوع، میتونه برای برنامهنویسهای تازهکارتر، کمی مشکلساز باشه. توصیه میکنم قبل از این که لقمه بزرگ بردارید و سراغ ریلز، جنگو یا لاراول برید حتما اول با سیناترا، فلاسک یا لومن کار کنید. به این شکل فرمورکها میتونن براتون به شدت قابل درکتر بشن.
خارج شدن شکل نرمافزار از کنترل توسعهدهنده(ها) : این مورد کمی پیچیدهست. فقط بذارید به این شکل بهتون بگم که شما مثلا یه سری واژه رو نمیدونید چطور مدیریت کنید. مثلا ممکنه اسم مدل مربوط به حساب بانکی رو Hesab, Bank یا Bank Account بذارید و نفر بعدی که روی کد شما کار میکنه، با این قضیه به مشکل بخوره. بهترین راه اینه که این موارد، قبل از پیادهسازی کشف و مستند بشن.
انعطاف پایین : طبیعیه که وقتی یک جعبهابزار کامل دم دستتون باشه، دیگه سراغ ساخت ابزار نمیرید. اکثر فرمورکهای MVC هم این مشکل رو دارند و اگر شما بخواهید بخشی هم خودتون پیاده کنید، به شدت به مشکل میخورید.
پرفرمنستایم پایین : خب از اونجایی که اکثر این فرمورکها، دارن همه چیز رو خودشون هندل میکنن، ممکنه هزینه بالایی برای اجرا داشته باشند. البته این هزینه ممکنه با توجه به سختافزارهای امروزی زیاد هم بالا حساب نشه، اما چرا وقتی میشه با کمترین هزینه کاری کرد، هزینه رو بیخود و بیجهت ببریم بالا؟
رفع اشکال پرهزینه : درسته که فرایند کشف و رفع باگ رو گفتیم که آسونه، اما هزینه بالایی داره. حواسمون باید به این موضوع باشه که داریم با چیزی کار میکنیم که همه چیش به همه چیش ربط داره و قطع این ارتباط میتونه هزینه زیادی وارد کنه بهمون.
بزرگ شدن غیرقابل کنترل پروژه : خب وقتی که MVC کار میکنیم، عموما خیلی کم پیش میاد که بخواهیم موجودیتها رو به صورت سرویسهای مجزا توسعه بدیم. در واقع اینجا خبری از میکروسرویس و اینا نیست! همین باعث میشه بیزنس از یک حدی که بزرگتر بشه، کنترلش به شدت سخت شه. از همین رو، معمولا در کنار MVC یک معماری دیگری مثل rest هم استفاده میشه که این داستانها رو نداشته باشیم.
حالا بیاید ببینیم چه راهحلایی برای این قضیه داریم؟ یک راه خیلی خوب اینه که وقتی مدلی ساخته میشه، کنترلر و ویوهای مربوطه هم اتوماتیک تولید بشن. بعدها میتونیم اون چیزی که نیاز نداریم رو از این چرخه حذف کنیم. خب چطوری؟ در این بخش، دو راه حل میارم. یکی از ریلز و دیگری لاراول (فکر کنم کسی انتظار لاراول رو در این قسمت نداشت).
راه حل Ruby on Rails
در ریلز یک مفهومی داریم به اسم scaffold. این مفهوم چی کار میکنه؟ میاد مدل، ویو و کنترلر یه موجودیت رو برای ما میسازه. برای زمانهایی که Rest API نداریم و میخواهیم صفر تا صد اپ رو خودمون بزنیم، یکی از بهترین انتخابها در ساخت و طراحی موجودیتها همینه.
مثال پست بلاگ رو در نظر بگیرید. چطوری میتونیم به سادگی همهچیش رو هندل کنیم؟! سادهست، کافیه این دستور رو تایپ کنیم:
rails generate scaffold Post title:string slug:string body:text
و این دستور به خودی خودش میاد و همه چیزهایی که نیاز داشتیم رو میسازه. خوبیهای این روش چیه؟
استاندارد بودن متدها در کنترلر (یعنی نیاز نیست دیگه زحمت مضاعف برای Routing بکشیم)
وجود viewهایی که پارامترهای درست ارسال و یا دریافت میکنن (کاهش هزینه کشف و رفع باگ در مراحل اولیه توسعه)
اما خب یک بدی بزرگ هم داره و اون اینه که خلاقیت شما رو میتونه کلا نابود کنه. برای اون هم راهکارهایی هست. مثل این که شما یه کنترلر مجزا بسازید و متدها و endpointهای مورد نظر خودتون رو اونجا تعریف کنید.
باقی موارد، همه مثل مطلب قبلیه و خب در مطالبی که در آینده نزدیک خواهم نوشت، حتما اشاره خواهم کرد به این موضوع که چه فعل و انفعالاتی در ریلز رخ میده برای ساخت این ماجراها 🙂
راهحل در لاراول
یک سلب ادعای کوچک ابتدای این بخش بکنم؟ عمده تجربه من با لاراول روی Rest API بوده و فرصتی نشده که MVC باهاش کار کنم. شاید هم هیچوقت MVC کار نکنم. اما این راهحل قطع به یقین برای MVC هم پاسخگوئه.
اول از همه یک مدل میسازیم:
php artisan make:model Post
و خب وارد جزییات نمیشم، میتونیم جزییات مدل رو در فایلهای مربوطه بررسی کنیم.
بعد برای این مدل به این شکل میتونیم کنترلر بسازیم:
البته لازم به ذکره که باید دقت داشته باشید همیشه کنترلرها از جنس resource و CRUD نیستن و این دو راهکار، در واقع برای وقتی خوبن که شما نیازمند CRUD باشید و نخواهید هزینه ساخت کنترلر «از بیخ» رو متحمل بشید.
جمعبندی مطالب
در دو مطلب، هم تعاریف مرتبط با MVC رو یاد گرفتیم، هم یه نیمچه اپ MVC نوشتیم و هم مزایا و معایبش و راهحلهای احتمالی برای معایب قضیه رو بررسی کردیم.
این مطالب، بیش از این که رنگ و بوی برنامهنویسی داشته باشند، مرتبط با مهندسی نرمافزار بودند و خوشحالم که در این زمینه هم محتوایی تولید کردم. فکر کنم این پست دیگه جمعبندی خاصی نیاز نداشته باشه. فقط خواستم بابت وقتی که برای خوندن این مطلب گذاشتید، ازتون تشکر کنم 🙂
احتمالا اگر با فرمورکهایی مثل جنگو، ریلز یا ASP کار کرده باشید، عبارت MVC رو به کرات مشاهده کردید. در این پست، قصد دارم تا در مورد این معماری توضیحاتی ارائه کنم. در هر بخش هم، یک مثالی از فرمورک روبی آن ریلز آوردم.
قبل از شروع بعنوان سلب ادعا عرض کنم که شما نیاز دارید که خودتون، روبی آن ریلز رو جداگانه یاد بگیرید و این مطلب، مطلقا آموزش روبی آن ریلز نیست.
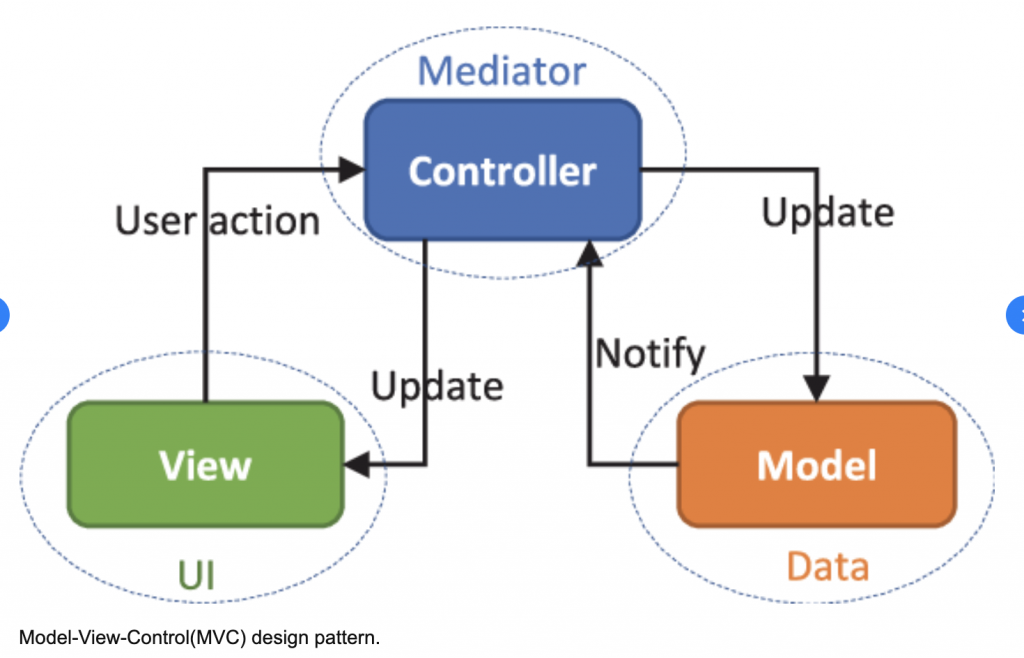
معماری MVC یعنی چی؟
خب MVC یک مخففه برای Model, View و Controller. در این معماری، یک نرمافزار (یا بهتره بگیم ایده/بیزنس) رو به سه موجودیت مدل، ویو و کنترلر تقسیم میکنیم و هر قسمت ایده یا بیزنس رو به یکی از اینها تبدیل میکنیم. در واقع، فرمورکها اینجان که ما فرایند ساخت این قضایا رو سریعتر پیش ببریم.
پس، بهتره جای این که صرفا دنبال زیربغل مار بگردیم، هر موجودیت رو جدا تعریف کنیم و ببینیم تهش به چی میرسیم!
مدل – Model
مدل، همونطور که از اسمش پیداست؛ یک مفهوم انتزاعی از یک موجودیته. بذارید یک مثال ببینیم. بیاید یک پست وبلاگ رو بررسی کنیم.
پست وبلاگ چیا داره؟ پست وبلاگ در نظر من اینها رو حتما داره:
عنوان که به عنوان یک رشته متنی در نظر گرفته میشه.
عنوان کوتاه یا slug که این هم یک رشته متنی در نظر گرفته میشه.
متن بدنه یا body که «متن» در نظر گرفته میشه.
توجه کنید که text از نظر اکثر فرمورکها با string متفاوته. این تفاوت رو احتمالا در مستندات فرمورکی که باهاش کار میکنید میتونید پیدا کنید.
حالا این مدل رو چطوری میسازیم؟ در ریلز به این صورت میتونیم یک مدل بسازیم:
rails generate model Post title:string slug:string body:text
بعد از اون هم به این شکل مایگرشنها رو اجرا میکنیم:
rails db:migrate
خب الان چی داریم؟!
الان چیزی نداریم جز یک مدل، که صرفا میگه «تعریف من از پست چیه». این تعریف کجا استفاده میشه؟ در دیتابیس. خب پس یعنی چی؟ بیاید یک تعریف کلی از مدل ارائه کنیم:
مدل عبارت است از تعاریف انتزاعی و ویژگیهاشون که در یک پایگاه داده ذخیره میشه.
خب، الان که میدونیم مدل چیه، چطور میتونیم یک نمونه ازش اجرا کنیم؟ برای نمونه در ریلز، ما اول کنسول ریلز رو باز میکنیم:
rails c
و سپس این دستور رو در کنسول وارد میکنیم:
Post.create(:title => "Hello, World", :slug => "hello-world", :body
=> "This is a first post made the wrongest way possible")
و به این شکل، ما یک پست ساختیم. اما آیا روش بهتری هم هست؟ بله هست!
کنترلرها – Controllers
طبیعتا وقتی به شما یک API داده میشه، از شما نمیخوان که با دستورات روبی پست بسازید، بهروز کنید یا حذف کنید! چیزی که به شما میدن چنین چیزیه:
GET /api/v1/posts
و این باید لیست همه پستها رو برگردونه. پس چطور این اتفاق میافته؟ با موجودیتی به اسم «کنترلر». کنترلر کارش چیه؟ کنترلر همونطور که از اسمش پیداست، میتونه کنترل کنه (یا بعبارتی چطور چشمبسته غیب بگیم؟). کنترلر وظیفهش انجام عملیات CRUD روی مدله.
حالا CRUD چیه؟ این هم یه مفهومی در بطن MVC و Rest API عه که باید بدونید چی به چیه و چی کار میکنه. عبارت CRUD مخفف Create, Restore, Update و Destroy عه. بیاید با هم دقیق بررسی کنیم:
حرف C یا Create : یعنی کنترلر باید بتونه برای من، یک نمونه از مدلم رو بسازه.
حرف R یا Restore (که در بعضی منابع Retrieve هم گفتن) : یعنی کنترلر باید بتونه محتوای یک مدل یا همه مدلها رو به من نشان بده.
حرف U یا Update : یعنی کنترلر باید بتونه در وضعیت یک نمونه از مدل، تغییری ایجاد کنه.
حرف D یا Destroy : یعنی کنترلر باید بتونه یک نمونه از مدل رو حذف کنه.
شما همون پست بلاگ رو در نظر بگیرید. این پست ممکنه نیاز داشته باشه که ویرایش بشه، نیازمند اینه که گاهی حتی حذف کامل بشه و … . این کار رو با کنترلر انجام میدیم. حالا چطوری یک کنترلر میسازیم؟ به این شکل:
rails generate controller api/v1/posts
سپس درون فایل کنترلر، این دو تابع رو برای حرف R اضافه میکنیم:
def index
@posts = Post.all
render json: @posts
end
def show
@post = Post.find(params[:id])
render json: @post
end
در یک تابع، قراره که کل پستها رو ببینیم و در یکی، فقط اونی که با ID مورد نظر ما درخواست شده نمایش داده میشه. خب، الان کافیه با ابزاری مثل curl تست کنیم API مون رو.
~/playground/mvc-tutorial/ [master] curl http://localhost:3000/api/v1/posts/1
{"id":1,"title":"Hello, World","slug":"hello-world","body":"This is a first post made the wrongest way possible","created_at":"2021-03-23T16:19:41.950Z","updated_at":"2021-03-23T16:19:41.950Z"}
حالا جهت این که C هم ببینیم، اون هم به کنترلر مربوطه اضافه میکنیم، اما بقیهش رو از مستندات ریلز میتونید یاد بگیرید 😁
پس این تابع رو به فایل کنترلرمون اضافه میکنیم:
def create
@post = Post.new(post_params)
if @post.save
render json: {:post => @post, :status => success}
else
render error: {:error => "Failed"}
end
end
این تابع چی کار میکنه؟ اول میاد از طریق یک تابع خصوصی به اسم post_params تعدادی از پارامترها مثل عنوان، عنوان کوتاه و متن بدنه رو دریافت میکنه، یک نمونه از مدل پست میسازه. اگر ذخیرهسازی پست با موفقیت انجام شه، محتوای پست رو به ما نمایش میده.
با ابزار curl به این شکل میتونیم از این بخش کنترلر استفاده کنیم:
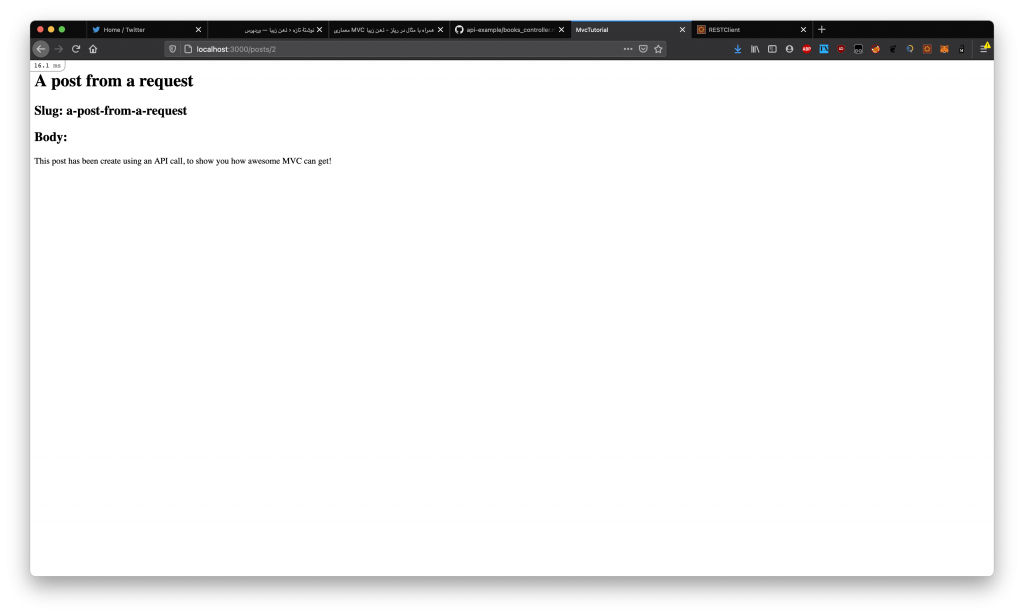
curl -X POST -H 'Content-Type: application/json' -i http://localhost:3000/api/v1/posts --data '{
"title":"A post from a request",
"slug":"a-post-from-a-request",
"body":"This post has been create using an API call, to show you how awesome MVC can get!"
}'
البته حواستون باشه در این مورد، حتما باید هدر Content-Type رو ارسال کنیم.
این هم نمونه جوابی که این تابع باید به ما بده:
{
"post": {
"id": 2,
"title": "A post from a request",
"slug": "a-post-from-a-request",
"body": "This post has been create using an API call, to show you how awesome MVC can get!",
"created_at": "2021-03-23T17:37:55.502Z",
"updated_at": "2021-03-23T17:37:55.502Z"
},
"status": "success"
}
اما خب، چطوری این داده رو میتونیم همینجا ببینیم؟! بدون این که از curl و … استفاده کنیم؟
ویوها – View
در بخش پیش، کنترلرها رو با دیدی که برای API و … داریم ساختیم. برای استفاده از ویو، یک بار دیگه یه کنترلر میسازیم:
rails generate controller posts
در این کنترلر این دو تابع رو قرار میدیم:
def index
@posts = Post.all
end
def show
@post = Post.find(params[:id])
end
خب قرار نبود این قسمت اینجاش با کد زدن شروع شه اما خب نیاز بود درک کنیم که ویو دقیقا چیه. خب، بیایم با دو تعریف آشنا شیم.
قابل خواندن برای ماشین (Machine Readable) : این مفهوم، به معنای دادههاییه که صرفا برای کامپیوتر قابل درک و خواندن هستن و برای کاربر، خواندنشون مشکله. مثل خروجی JSON یا چیزایی که تو دیتابیس ذخیره میکنیم. وقتی از روی API دادهای میفرستیم، در واقع دادهها رو به صورت قابل خواندن برای ماشین میفرستیم و دریافت میکنیم.
قابل خواندن برای انسان (Human Readable) : این مفهوم، به معنای دادههاییه که برای انسان قابل خوندن هستند. مثل همین پستی که شما دارید میخونید. در واقع این پست در یک دیتابیس MySQL به شکل عجیب و غریب (برای انسان) ذخیره شده و وقتی شما روی لینکش کلیک میکنید، به شکل قابل خواندن برای انسان درمیاد.
اگر صرفا API داشته باشیم، کار ما MVC نیست، اما میتونیم ویو رو با استفاده از Front End داشته باشیم (که در آینده در مورد اون هم یک مطلب خواهم نوشت). اما میتونیم بیایم و برای حداقل همون حرف R یک ویو بسازیم (در حقیقت دو تا). چرا؟ چون بعضی وقتا ممکنه برنامهنویس فرانت نداشته باشیم، بعضی وقتا ممکنه حتی نیازی به فرانت نباشه و … .
برای ساخت ویو در ریلز، نیازی به اجرای دستوری نیست. در این فرمورک، وقتی کنترلر بسازید در پوشه:
app/views
یک پوشه به اسم کنترلر مربوطه ساخته میشه. پس در پوشه:
app/views/posts
دو فایل به اسمهای index.html.erb و show.html.erb ایجاد میکنیم.
در فایل index.html.erb این موارد رو باید داشته باشیم:
<h1> Posts </h1>
<% for post in @posts %>
<ul>
<li>
<a href="/posts/<%= post.id %>"> <%= post.title %></a>
</li>
</ul>
<% end %>
همونطور که میبینید، این کد دو تفاوت اساسی با HTML معمولی داره :
پسوندش یه ERB اضافه داره
کد روبی وسطش زده شده.
خب، این زبون، HTML نیست (بله، HTML هم زبانه، فقط «زبان برنامهنویسی» نیست!) بلکه زبان تمپلیتینگ خود روبیه. مثل blade در php یا Jinja در پایتون.
حالا اگر با مرورگر به localhost:3000/posts بریم این صحنه زشت رو میبینیم 😁
و اگر روی لینکها کلیک کنیم، وارد پستها میشیم:
البته یادتون باشه slug معمولا برای url کاربرد داره ولی چون اینجا قصد آموزش ریلز نبود، از این ماجرا صرف نظر کردیم.
خب، حالا بعد یک مطلب طولانی، میدونیم که چی به چیه؛ بیاید با هم جمعبندی کنیم.
جمعبندی مطلب
اول از همه در این مطلب به یک تعریفی برای MVC رسیدیم. در واقع، کار ما بعنوان یک مهندس نرمافزار، تبدیل مفاهیم و موجودیتهای یک بیزنس و روابطشون با هم به یک سری مدل، کنترلر و نحوه نمایششون به کاربر در فرم ویو خواهد بود. حالا که یک تعریفی از MVC داریم، به نظرم بد نیست که بیایم هر مورد هم یک بار دیگر، بررسی کنیم.
مدل : مدلها، تعاریف انتزاعی از موجودیتها، ویژگیها و روابط بینشون هستند. به عبارتی، شکلی که ما قراره داده خام رو پردازش کنیم، در مدل تعیین میشه. کمی راحتترش کنم؟ مدل در واقع ساختار دیتابیس ماست.
کنترلر : کنترلر وظیفه ساخت یک نمونه از مدل، استخراج داده از دیتابیس، بروزرسانی داده در دیتابیس و حذف یک رکورد از دیتابیس رو عهده داره. این هم اگر بخوام راحت توصیف کنم، میگم ابزاری که باهاش دیتابیس رو به شکل سادهتری کنترل میکنیم.
ویو : ویو، نتیجه یک کوئری رو به صورت قابل خواندن توسط انسان، به ما نمایش میده. نتیجه کوئری معمولا به صورت یک جدول در دیتابیس (در واقع یک یا چند سطرش) یا به صورت JSON برمیگرده که توسط انسان قابل خوندن نیست. ما در ویو (و البته اغلب فرانت) این اتفاق رو رقم میزنیم.
البته موارد دیگری هم هستند که دیگه واقعا از حوصله این مطلب خارج شدند. دلیل عمدهش؟ طولانی شدن بیش از حد این مطلب. وگرنه دوست داشتم از معایب و مزایای MVC هم حرف بزنم. یک اتفاق بامزه هم این وسط افتاد که من حتی مجبور شدم لپتاپ رو ریبوت کنم و شانس آوردم که دو سه ساعت فکر و نوشتن، نپریده بود 😂
در پایان، از همه شمایی که این مطلب رو خوندید تشکر میکنم که وقت گذاشتید بابت خوندن مطلب. ضمنا، این اتفاقات در فرمورکی که شما استفاده میکنید چطوری رقم میخوره؟ در نظرات منتظرتونم 🙂
در دنیای امروزی، بخش بسیار بزرگی از بیزنس و همچنین توسعه نرمافزار مرتبط به توسعه عملیات (Dev Ops)، مدیریت سیستم (System Administration) و همچنین استقرار و یکپارچگی ادامهدار (CI/CD) میشه. شاید حتی مهمتر از اصل نرمافزار، رسیدگی به این موضوعات باشه. در این پست، قراره که با هم بررسی کنیم چطور میتونیم در پایان روز، به خودمون بگیم DevOps Engineer؟ و چه چیزایی باید بلد باشیم؟ 🙂
مدیریت سیستم یاد بگیرید
یادگیری مدیریت سیستم، بخش «عملیات» قضیه رو معمولا شامل میشه. پس لازمه که اینجا چیزایی رو بلد باشیم که معمولا در شرکتها و سازمانهای بزرگ بهشون نیاز میشه. اما قبل از اون، لازمه که یه چیزایی رو به صورت عمومی بلد باشیم. پس بیاید با هم بررسی کنیم که عمومیات دواپس شدن چیا هستن؟
یادگیری لینوکس. عموم شرکتها در دنیا در حال حاضر، سرورهای لینوکسی دارند. بلد بودن لینوکس، یک «باید» در یادگیری دواپس محسوب میشه. یادگیری لینوکس اصلا سخت نیست. کافیه یک توزیع خاص (مثل اوبونتو) رو نصب کنید و باهاش بازی کنید. کم کم دستتون میاد که چی به چیه. بعد از این ماجرا، میتونید یک سرور اجاره کنید و چیزایی که یاد گرفتید رو روش تست کنید.
آشنایی با وبسرورها. وبسرورها، نرمافزارهایی هستند که به شما امکان نمایش نرمافزار و محتوای تولیدی از طریق پروتکل HTTP رو میدن. در دنیای امروز اکثریت قریب به اتفاق کسب و کارهای کوچک و حتی بزرگ، از NGINX استفاده میکنن. پس بد نیست بعد از این که لینوکس یاد گرفتید، روی سرور یا ماشین مجازی لینوکسیتون یک وبسرور نصب کنید و سعی کنید یک صفحه استاتیک باهاش نمایش بدید.
آشنایی با شبکه. گرچه معمولا این مورد رو باید اول از همه بیاریم، اما من شخصا معتقدم که یادگیری لینوکس در بحث مدیریت سیستم به هرچیزی ارجحه. اما از این موضوع که بگذریم، چرا شبکه؟ شبکه پایه و اساس دواپسه. شما بدون بلد بودن شبکه، تقریبا هیچ کاری نمیتونید بکنید. اما چه حد شبکه بلد بودن خوبه؟ دقت کنید که اینجا قرار نیست ما نیروی آیتی یک سازمان باشیم، پس فقط کافیه که پایههای شبکه، آیپی و بعضی پروتکلهای مرسوم (SSH, FTP, HTTP, SMTP و …) رو بدونیم و بدونیم که هرکدوم چطور و کجا کار میکنند.
آشنایی با فایروال و تامین امنیت شبکه. فکر کنم عنوان خودش گویاست. در لینوکس، ما معمولا از iptables یا اینترفیسهایی که براش ساخته میشن (مثلا اوبونتو UFW و دبیان apparmor رو دارند) استفاده میکنیم. این خیلی مهمه که شما بعنوان مدیر سیستم، در جریان باشید که چه چیزایی از بیرون در دسترسه و این حجم از دسترسی، چقدر میتونه آسیبزا باشه.
موارد بالا، مواردی هستند که حتما باید بلد باشید. فرقی هم نمیکنه که جایی استخدام شدید یا اگر قراره بشید، ازتون خواستند بلد باشید یا نه. در واقع «باید»های مدیریت سیستم موارد بالان.
اما در بسیاری از شرکتها یک سری سناریو خاص وجود داره که اینها رو میتونیم با هم بررسی کنیم، گرچه قرار نیست همه موارد رو با هم یاد بگیریم، اما چیزایی که به نظرم ممکنه وجود داشته باشند رو در اینجا بررسی میکنم.
استفاده از یک ابر خصوصی به جای چندین سرور عمومی. این مورد، مورد خوب و امنیه. گذشته از این که باعث میشه خیلی از موارد (مثل دیتابیس و …) از بیرون در دسترس عموم قرار نگیرند، هزینهها رو هم پایین میاره. فقط حواستون باشه که در این مورد، معمولا چند چیز اتفاق میافته که باید بلد باشید:
استفاده از لود بالانسر : لود بالانسرهای مرسوم مثل haproxy میتونن نقطه شروع خوبی باشن. البته این هم در نظر داشته باشید که معمولا ارائهدهندگان سرویسهای ابری؛ خودشون هم لود بالانسینگ رو انجام میدن.
استفاده از سیستمهای مانیتورینگ : طبیعتا شما برای این که ببینید هرکجا چه اتفاقاتی میافته، نیاز به یک سیستم مانیتورینگ خوب دارید. در حال حاضر سرویسهایی مثل prometheus و zabbix وجود دارند. همچنین میتونید اینها رو به grafana و امثالهم متصل کنید و به شکل زیبایی، اونها رو ویژوالایز کنید.
استفاده از نرمافزارهای بیلد شده به صورت سفارشی. گرچه این مورد رو شخصا درک نمیکنم (چون نسبت به نرمافزاری که از کانال رسمی – مثل مخزنهای توزیع لینوکستون – نصب میکنید ممکنه امنیت و پایداری کمتری نشون بدن) اما برخی سازمانها ممکنه وبسرور، کامپایلر یا مفسر یا حتی کرنل رو خودشون از نو بیلد کرده باشن. پس یادتون باشه این مورد هم تا حدی یاد بگیرید که اگر نیاز به بیلد مجدد شد گیر نکنید 😁
در مورد مدیریت سیستم به قدر کافی یاد گرفتیم، دیگه چی میمونه؟ نظر من رو بخواید الان وقتشه که یک سری ابزار رو با هم بررسی کنیم. توجه کنید که ابزارهایی که در این بخش ازشون حرف میزنم، ابزارهایی هستند که خودم باهاشون تجربه کار دارم. فلذا اگر ابزاری از قلم افتاده، در بخش نظرات در مورد ابزارهای مورد نظر خودتون صحبت کنید. من خوشحال میشم 🙂
ابزارهایی که باید یاد بگیرید
وبسرور
گرچه این رو در بخش قبلی اشاره کردم، در اینجا میخوام صرفا کمی در مورد NGINX حرف بزنم. یادتون باشه که NGINX امروزه یک انتخاب خوبه چون:
در بسیاری از توزیعها، وجود داره. در حدی که خیلی از توزیعهای سروری رو وقتی نصب کنید؛ ممکنه همراهش نصب شده باشه.
پیکربندی به شدت سادهای داره (و خب کاش حداقل نیاز نبود ته هر خط پیکربندی شما یک سمیکالن بذاری)
ابزارهای جانبی بسیار خوبی مثل python3-certbot-nginx براش ساخته شده که امکان SSL و … گرفتن برای دامنه خاص و زیردامنهها و … رو به شدت ساده میکنه.
تقریبا برای هرکاری یه آموزشی ازش هست!
ابزارهای CI/CD
خب ابزارهای CI/CD چی هستند؟ به صورت کلی، این ابزارها اینجان که کار استقرار (Deploy) و یکپارچگی (Integration) هرآپدیت با نسخه قبلی رو اتوماتیک انجام میدن. ابزارهای زیادی برای این کار وجود دارند من جمله Travis CI, Jenkins و البته معروفترینشون Gitlab CI/CD (حداقل در ایران).
این ابزارها به این شکل عمل میکنن که یه سری فایل پیکربندی (در مورد گیتلب از نوع YML ) دریافت میکنند و اون رو بررسی میکنند. سپس مطابق اون، عملیات رو انجام میدند و نرمافزار شما رو مستقر میکنن. خوبی گیتلب در این زمینه اینه که به ازای هر بهروزرسانیای که شما انجام بدید، یک بار Pipeline اجرا میکنه و بروزرسانیها رو روی سرور مورد نظر اعمال میکنه. البته باقی ابزارها هم امکان اتصال به گیت رو دارند پس نگران نباشید.
ابزارهای مانیتورینگ
طبیعتا بالا بودن یا نبودن سرویسها، دیتابیس، سرویسهایی که از بیرون دریافت میکنیم و یکپارچگی داریم باهاشون، مهمن. همینطور ظرفیتی که در دیسک و حافظه و … اشغال شده هم مهمه که دونسته بشه. فلذا اینجا لازمه که ابزاری باشه که اینجا بیاد و این رو برای ما چک کنه.
این ابزار معمولا چیه؟ خب ابزارهای زیادی براش هست و من تجربهم استفاده از prometheus بوده. پرومتئوس یک سری ابزار خاص داره که بهش میگن exporter. شما روی هر قسمتی که نیاز دارید (مثلا nginx یا خود سرور که بهش میگن node یا هرچیزی از این قبیل) یک اکسپورتر نصب کنید و نتایج آنالیزها رو اینجا ببینید.
همچنین نتایج معمولا روی پرمتئوس زیبا نیستن، به همین خاطر شما میتونید یک ابزار بهتر مثل Grafana نصب کنید و نتیجه رو به شکل قشنگی visualize کنید. همچنین میتونید روی هرکدوم یک سیستم alerting ست کنید که از روشهای مختلفی مثل پیامک، ایمیل یا حتی پیام در اسلک بهتون هشدار بده که کجا چی درست نیست.
ابزارهای ذخیرهسازی
خب، این هم یه چیزی که شاید کمتر ازش با خبر بوده باشید :). در دنیای امروز تقریبا کسی نیست که رو همون سروری که نرمافزارش هست، فایل ذخیره کنه. پس چی کار میکنن؟ هیچی، اونجاهایی که جزء دنیا حساب میشن؛ معمولا از Amazon AWS استفاده میکنن و پارتیشن S3 دریافت میکنن. S3 یعنی Simple Storage Solution (سه تا S) و خب این حقیقت وجود داره که راهکار بهتریه. چرا؟ چون شما برای ذخیرهسازی صرفا هارد نیاز داری و نه پردازنده یا رم زیاد.
اما نگران نباشید، اگر به هر دلیلی دسترسی به AWS ندارید، میتونید در همین ایران از ابزارهایی مثل ابرآروان و پشتیبان هم استفاده کنید. فقط کافیه که یاد بگیرید که چطور نرمافزار رو با S3 یکپارچه کنید (اینجا اهمیت این ماجرا که مهندس دواپس نیازمند اینه که دانش برنامهنویسی داشته باشه مشخص میشه) و دستورالعملهای لازم رو به توسعهدهندهها بدید؛ یا این که اصلا خودتون کدبیس رو درک کنید و این یکپارچهسازی رو انجام بدید.
یک راه دیگه هم داشتن سرور با حجم بالای هارددیسک (در ابعاد ترابایت) میتونه باشه. بعد از اون شما نیاز دارید تا یک نمونه S3 روی اون مستقر کنید. برای این کار میتونید از ابزاری مثل minio بهره بگیرید.
ابزارهای ارکستراسیون
ابزارهای ارکستراسیون چی هستند؟ ارکستر در موسیقی، به معنای «گروهی از نوازندگان»ــه. یعنی یک گروهی که مثلا دو نفر ویولن میزنن، یک نفر ویولا و یک نفر چلو. در دواپس ارکستر به مجموعهای از سرورها یا شبکهها گفته میشه که یک کار انجام میدن. تا حالا دقت کردید چطوریه که شما سرعت کارتون با توییتر در آلمان با سرعت کارتون با توییتر در آمریکا یکیه؟ یا مثلا چطوریه که شما از ایران یک عکس رو پست میکنید و مثلا خاله شما در آمریکای شمالی اون رو لایک میکنه؟!
علتش اینه که این نرمافزارها به عبارتی Orchestrate میشن (فارغ از بحث CDN و …) یعنی از یک نرمافزار و همچنین دیتابیسشون (البته دیتابیس Cache و نه دیتابیسهای اصلی) بیش از یک نمونه در حال اجراست. برای شما سوال نشده که اینا چطور هندل میشن؟ خب جواب اینه که ابزارهای ارکستراسیون استفاده میشه.
از بین این ابزارها میشه به Docker Swarm و Kubernetes و Ansible اشاره کرد. طبق تجربه با Ansible به شما بگم که شما تنظیماتی که نیاز دارید رو مشابه CI/CD در یک سری فایل پیکربندی (انسیبل بهشون میگه استوری) مینویسید و مجموعهای از استوریها رو در یک namespace قرار میدید. مثلا فرض کنید همین وبلاگ کجاها قراره باشه، من یه namespace به اسم haghiri75 میسازم و اطلاعات استقرار رو بهش میدم.
با ابزارهای ارکستراسیون، آمادهسازی و پیادهسازی سناریوهای سرور و یا ابر خصوصی به شدت سادهتر و سریعتر خواهد شد.
بسیار عالی، این بخش هم تمام شد. یک بخش کوچک هم مونده که اون هم میخونیم و بعدش این دفتر هم به پایان میرسونم. تا اینجا اگر خوندید، یکم به خودتون استراحت بدید. بعد بخش بعدی رو بخونید و یادتون نره که این مطلب رو با دوستانتون به اشتراک بذارید.
برنامهنویسی یاد بگیرید
بسیار خوب، در این بخش که در واقع بخش پایانی این مطلب در مورد اینه که چطور DevOps بشیم، لازمه اشاره کنم به این که نیاز دارید برنامهنویسی بلد باشید. حالا به چه زبونی و در چه حد؟ اینها مهمن. خب در این قسمت یکم در مورد زبانهایی که «باید» بلد باشید صحبت میکنم و بعد از اون هم راهنمایی میدم در مورد زبانهایی که احتمالا در جریان کار مجبورید باهاشون کار کنید.
پایتون، از چیزایی که باید بلد باشید!
چرا پایتون؟ خب پایتون این روزها طوریه که شما حتی مهندس کامپیوتر یا توسعهدهنده هم نباشی احتمالا دوست داری یادش بگیری و خیلیها کم و بیش پایتون رو بلدند. اما چرا بعنوان یک مهندس دواپس باید پایتون بلد باشیم؟
بر خلاف گذشته که خیلی از پیکربندیهای سرور با پرل انجام میشد، سالهاست که توزیعهای مطرح لینوکس مثل اوبونتو، ردهت، دبیان، سنتاواس و … دارند میرن سمت پایتون. پس به نوعی شما زبانی رو یاد گرفتید که برای پیکربندی سرور داره استفاده میشه و عملا ضرری نکردید.
ابزارهای مانیتورینگ و همچنین پنلهایی که براشون ساخته شده هم معمولا پایتونی هستند. حداقل گرافانا که با پایتون نوشته شده و دونستن پایتون میتونه در بهبود کارکرد این قضیه به شما کمک بده.
احتمال خوبی هم وجود داره که نرمافزاری که میدن به شما تا مستقر کنید هم پایتونی باشه، فلذا پیادهسازی بخش دواپسی قضیه هم میتونه براتون سادهتر باشه.
و در نهایت؛ شما ممکنه ابزاری نیاز داشته باشید که موجود نباشه. پس خودتون باید پیادهش کنید. با پایتون این قضیه به شدت سریع اتفاق میافته.
یک زبان سیستمی
زبانهای سیستمی، زبانهای برنامهنویسی هستند که برای توسعه ابزارهای سیستمعامل استفاده میشن، برای تعامل با سختافزار پرفرمنس بهتری دارند و در نهایت برای ایجاد ابزارهای زیرساختی مناسبترند. اینجا نمیخوام شما رو به یادگیری اسمبلی تشویق کنم، بلکه ازتون خواهش میکنم همیشه نیمنگاهی به زبانهایی مثل Rust یا Go داشته باشید (و در نظر بگیرید که Go حتی در بکند هم استفاده میشه فلذا یادگیریش خالی از لطف نیست!).
زبانی که سازمان ازش استفاده میکنه
این هم نیاز به گفتن نداره. شما نیاز دارید تا کدبیس رو یاد بگیرید و درکش کنید. حداقل وقتی که قراره دواپسیجات رو روی کد اعمال کنید این مهم خودش رو نشون میده. نگران هم نباشید، معمولا DevOps درگیری به شدت کمتری با کدبیس مستقیم درگیر میشه. پس اگر حس و حال کار تو تیم توسعهدهندهها رو ندارید نگران این مورد هم نباشید :))
خب این دفتر هم به پایان رسوندم. جا داره در انتها، یک نکته خیلی مهم رو عارض بشم خدمت شما. سعی من کلا بر این بود که مطلبم خیلی مرتبط به یک دوران خاص از تاریخ نباشه و مثلا ۳ سال بعد هم قابل استفاده باشه. همچنین، این رو یادتون باشه که این مطالبی که در اینترنت موجودند، معمولا تجربیات شخصی هستند.
شخصا معتقدم تجربیات ارزشمندن، اما یه نکته مهم اینه که تجربهها یکسان نیستند. مثل همین مطلب، مطلبیه که من طی تجربه خودم بهش رسیدم و ممکنه شما مسیر متفاوتی رو در سفرتون به دنیای دواپس طی کرده باشید. به همین خاطر هم کل مطلب رو در یک جمله خلاصه میکنم که «فرمول کلی برای دواپس شدن وجود نداره».
امیدوارم مطلب مفیدی بوده باشه، در نهایت هم سال نوتون پیشاپیش مبارک 🙂
وبلاگ شخصی محمدرضا حقیری، برنامهنویس، گیک و یک شخص خوشحال
 شرکت در لاگها و رویدادها و آخر و عاقبت پروژه جبیر
شرکت در لاگها و رویدادها و آخر و عاقبت پروژه جبیر