از زمانی که مدلهای هوش مصنوعی متنی یا همان مدلهای بزرگ زبانی (Large Language Model) مثل ChatGPT ارائه شدند، همیشه یک مشکل بزرگ داشتند، این که زباننفهم بودند! در واقع این زبان نفهمی در مدلهای کوچکتر مثل مارال شاید بیشتر دیده میشد اما منظور و مقصود این مطلب، هذیانگویی یا درک نکردن مطالب ورودی نیست، بلکه عدم درک درست از ابزارهاییه که به خورد مدلها داده میشه. این مساله، در ابتداء با عوامل هوش مصنوعی یا همان ایجنتها حل شد. ساخت یک ایجنت کار بسیار سادهایه و خب این موضوع اینجا پوشش داده شده و میتونید اون رو بخونید.
اما در سال گذشته شرکت Anthropic که سازنده مدل Claudeئه ابزاری ارائه کرد به اسم MCP که باید ببینیم چیه و چطور کار میکنه. در این پست، تمام تلاشم اینه که به سادهترین زبان ممکن، MCP Serverها و این که چطور مشکل زباننفهمی رو حل کردند رو برای شما توضیح بدم چون تا جایی که گشتم مطالب فارسی خوبی در موردش نبود یا اگر هم بود، در صفحات اینستاگرامی و تلگرامی بود که در وب قابل دسترسی نیستند.

اصلا MCP چیه و چطور کار میکنه؟
خب این یک سوال خیلی مهمه. ابتدا باید ببینیم MCP یعنی چی و چطور کار میکنه و چرا انقدر مهمه. پس اول بیایید یک فرض داشته باشیم. این فرض ممکنه خیلی شبیه به تست اتاق چینی (یکی از تستهای مطرح و مشهور هوش مصنوعی) به نظر بیاد و خب تا حد زیادی همونه. اول اتاق چینی رو توضیح میدم و بعد یک مثال ملموستر میزنم و بعد میریم سراغ ادامه ماجرا.
تست اتاق چینی به این شکله که اگر شما در یک اتاق گیر بیفتید و یک سری ابزار و وسایل باشه، همراه اونا هم یه سری راهنما به زبان چینی، احتمالا صرفا با دنبال کردن نمادهایی که در راهنماها وجود داره میتونید در اون اتاق زنده بمونید و یا ازش بیایید بیرون. این موضوع در زبانآموزی و مثال ملموستر ما، کاربردیه. چطور؟
فرض کنیم شما بخواهید زبان اسپانیایی یاد بگیرید (زبانی به شدت راحتتر از چینی) و خب احتمالا یکی از کارهایی که میکنید اینه که زبان گوشی یا رایانه شخصیتون رو به زبان اسپانیایی تغییر میدید. در این حالت جاهای آشنا رو میبینید. مثلا میتونید درک کنید که دکمههای قرمز احتمالا برای پاک یا متوقف کردن هستند، دکمههای سبز برای تایید و اجرا و الی آخر.
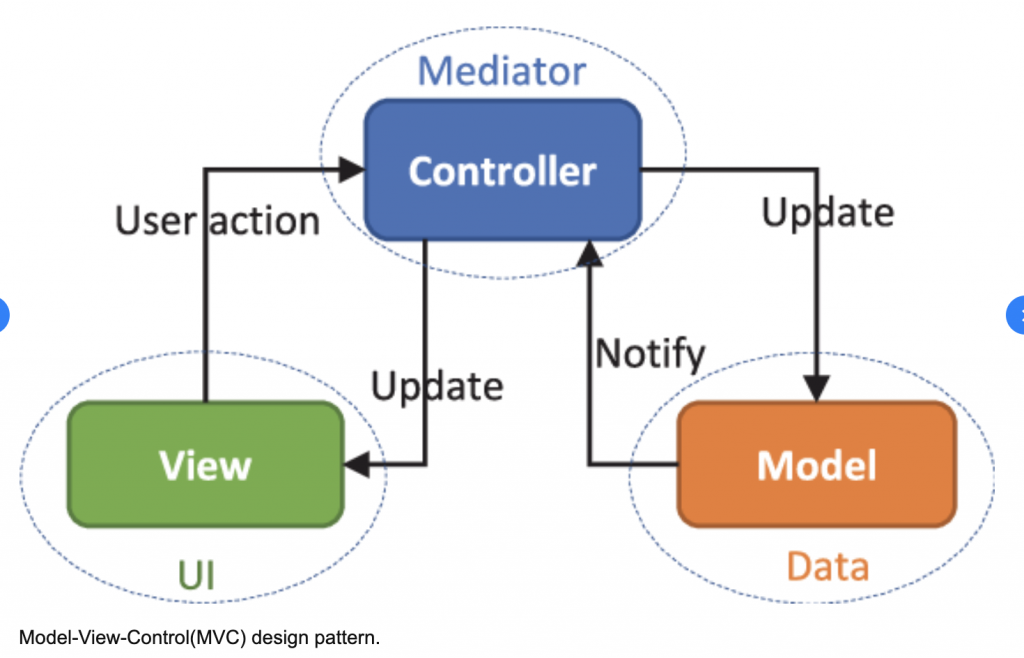
حالا MCP دقیقا همینه، یک راهنماست که مدل هوش مصنوعی بتونه از اتاق چینی بیاد بیرون. چطوری؟ با کمک Context. در واقع اسمش روشه Model Context Protocol یا «شیوهنامه متن مدل». و حتی چیز خیلی جدیدی هم نیست، فقط یک روش متفاوت از روشهای پیشینه که برای اجرای ایجنتها داشتیم.
ساز و کار MCP زیر ذرهبین
به جای این که این قسمت رو با دیاگرامهای غیرقابل فهم پر کنم، خیلی ساده در مورد یک مساله فرضی توضیح میدم و MCP رو بیشتر میشکافم.
اول از همه، اگر دقت کنید اکثر MCP ها عنوان Server رو یدک میکشن، یعنی یک خدمتی ارائه میدن. پس کلاینت ما اینجا، خود مدل هوش مصنوعیمونه. مثلا Claude, ChatGPT یا حتی مدلی که توسط Ollama داریم روی کامپیوتر شخصیمون ران میکنیم.
یک سناریوی فرضی داریم. مثلا شما میخواهید از جایی مثل «اسنپفود» سفارش ثبت کنید. وارد رابط هوش مصنوعی میشید و بهش میگید «برای من از رستوران X یک کارامل ماکیاتو ۱۰۰٪ عربیکا سفارش بده».
حالا چه اتفاقاتی در پشت صحنه رخ میده؟
- اول، MCP Server لیست ابزارهای خودش رو برمیگردونه. اینجا میتونه list_cafes باشه، میتونه get_order باشه و … . هرکدوم از این ابزارها، همراه یک توضیح ریزی بر میگردند. شبیه به چیزی که در Open API یا همون Swagger داریم.
- اینجا مطابق ابزارها و توضیحاتشون، مدل ما باید درخواست رو بشکنه. پس چه کار میکنه؟
- طبق پرامپت اولیه ما، اسم رستوران رو تشخیص میده و منوش رو از ابزار مورد استفاده، دریافت میکنه.
- با ابزار جست و جو در منو، درک میکنه آیا کارامل ماکیاتو به صورت ۱۰۰ عربیکا موجود دارند یا نه. ممکنه اینجا از ابزار «بررسی موجودی» هم استفاده کنه.
- در صورت موجود بودن، ممکنه به ما بگه موجوده و قیمتش ۱۰۰ هزار تومان به ازای هر فنجانه. ۲۰ هزار تومان هم هزینه ارسالش به آدرس شماست.
- اینجا شما میگید «بسیار عالی سفارش رو ثبت کن».
- بعد اینجا، ابزار ثبت سفارش رو صدا میزنه. بعد از اون، به شما یک سفارش تایید نشده میده، همراه لینک پرداخت. بعد از پرداخت شما، احتمالا یک ریکوئست دیگه میره سمت سرور که چک کنه پرداخت شده یا نه. حتی اینجا ممکنه شماره پرداخت و … هم از شما دریافت بشه که با ابزار متناسب، چک کنند آیا این پرداختی انجام شده که سفارش انجام شه یا خیر.
- بعد از اون شما صرفا با «چت کردن» میتونید از وضعیت سفارشتون آگاه شید.
- پس از این، هربار بخواهید سفارشی ثبت کنید، یک MCP بین شما و اسنپفود هست که سفارشتون رو مثل سابق (زنگ زدن به رستوران و درخواست یک سفارش خاص) ثبت و پردازش کنه.
عملکرد MCP به این شکله و خب همونطوری که میبینید، در واقع به جای این که چند ابزار رو به زور بخواهیم به خورد مدل زبانی بدیم، همه رو میبریم زیر پرچم یک ابزار و اون رو تبدیل میکنیم به یک MCP سرور.
مزایا و معایب MCP ها
طبیعتا وقتی یک ابزار جدید معرفی میشه، مزایا و معایب اون هم باید زیر نظر داشته باشبم. به همین خاطر، اینجا مزایا و معایبی که خودم بهش رسیدم رو هم براتون لیست میکنم که خب شاید در استفاده از MCPها مد نظر داشته باشیدش.
مزایای MCPها
- استانداردسازی ارتباط با ابزارها: از اونجایی که MCP یک پروتکل یا شیوهنامه به حساب میاد، میشه گفت که همه چیز رو به شکل استانداردی درمیاره. پس این موضوع، موضوع مهم و حائز اهمیتی خواهد بود. در واقع میدونیم که یک استاندارد جامع داریم که مدلهای زبانیمون بتونن بفهمنشون.
- کنترل بهتر روی جریان داده: از اونجایی که وظیفه اصلی مدل زبانی ما میشه تبدیل محتوای «قابل خواندن برای انسان» یا Human Readable به محتوای «قابل خواندن برای کامپیوتر» یا Machine Readable (محتوایی مثل XML, JSON, YAML و …) کنترل بهتری روی جریان دادهها هم خواهیم داشت. در واقع میتونیم اینجا دادههای ورودی کاربر رو هم ذخیره کنیم و مورد بررسی قرار بدیم (طبیعتا با اطلاع کاربر).
- مقیاسپذیری: یکی از بزرگترین گلوگاههای بیزنسهای هوش مصنوعی، همیشه مقیاسپذیری نسبتا پایینیه که دارند. تقریبا هرجایی که مانی رو پرزنت میکردم، بعد از این سوال کلیشهای مسخره که با میدجرنی چه فرقی داره میپرسیدند شما چطوری اسکیل میکنید؟ خب MCPها این مساله رو هم حل میکنند. در واقع میتونن برای چند مدل، چندین و چند کاربر و … همزمان کار کنند و مشکلات مرتبط رو به راحتی کاهش بدن.
معایب MCPها
- پیچیدگی در پیادهسازی اولیه: از اونجایی که میشه MCPها رو نوعی از IaC یا Infrastructure as Code دونست، میشه گفت این مشکل جهانشمول پیادهسازی اولیه طولانی رو همه ابزارهای اینچنینی دارند. حداقل روی خوب ماجرا اینه که این کار «فقط یک بار» انجام داده میشه و بعدش نیاز به تکرار مکررات نیست.
- وابستگی به کیفیت مدل: طبیعتا مدلی مثل Gemma 27B با مدلی مثل OpenAI GPT 5 در کیفیت یکسان نیست و باید این رو هم خودتون و هم مشتریهای احتمالیتون در نظر بگیره. حالا باز با استفاده از مدلهای بزرگتر، این مشکل تا حد زیادی پوشش داده میشه. یعنی رفتن سمت مدلی مثل GLM یا Kimi K2 یا DeepSeek V3.1 و …، این مسائل رو میتونیم تا حد بسیار خوبی حل کنیم.
- استفاده زیاد از توکن: در نهایت، از اونجایی که هربار مدل رو در نقش «کلاینت» قرار میدیم، تعداد زیادی توکن مصرف میشه که البته این موضوع هم تا حد خیلی خوبی، توسط شرکتهایی مثل Cloudflare یا حتی خود آنتروپیک، در حال حل شدنه که در آینده نه چندان دور در موردش خواهم نوشت.
همانطور که میبینید، MCP هم روش خالی از عیب و ایرادی نیست ولی روش مطمئن و خوبی برای اجرای ابزارهامون از طریق مدلهای زبانیه. شما میتونید از این روش استفاده کنید و مثلا گوگل کلندر یا اینستاگرامتون رو مدیریت کنید یا چند مدل رو به هم متصل کنید و یک ابرابزار بسازید. در نهایت، همه چیز برمیگرده به این که خودتون قصد انجام چه کاری داشته باشید.

سخن پایانی
در پایان باید این موضوع رو متذکر بشم که هوش مصنوعی، مثل همه ابزارهایی که تا الان ازش استفاده کردیم، یک ابزاره. یک ابزار برای پیشبرد کارهامون و به قول سرمایهگذاران سیلیکونولی، برای انجام کارهای بیشتر در زمان کوتاهتر و خب دلیل محبوبیت و جذابیت زیادش هم برای عموم مردم، تا الان همین بوده. هرچیزی که هم که حول هوش مصنوعی ساخته شده مثل همین MCP ها، دقیقا برای اینه که زندگی ما راحتتر بشه و کارهای تکرار پذیرمون کمتر.
اگر علاقمند به محتوای هوش مصنوعی در این سبک هستید، علاوه بر این بلاگ میتونید کانال تلگرام من رو هم دنبال کنید و اونجا هم مطالب کوتاه و اخباری که در این مورد مینویسم رو مطالعه کنید.




 آیکیا: کسب و کار اضافه کردن تخم مرغ به پودر کیک
آیکیا: کسب و کار اضافه کردن تخم مرغ به پودر کیک