خیلی از افرادی که این روزها، میخوان پروژههایی در حوزههای مختلف هوش مصنوعی مثل یادگیری ماشین، یادگیری عمیق، علوم داده و … انجام بدن یک گلوگاه بسیار بزرگ دارند و اون «داده» است. خیلیها واقعا نمیدونن از کجا میتونن دادههای مناسب پروژههاشون به دست بیارن. در این مطلب، قراره که این موضوع رو پوشش بدم.
منابع مناسب داده برای پروژههای شما
در این بخش، با هم چندین منبع مناسب برای پیدا کردن داده رو بررسی خواهیم کرد. فقط قبل از هرچیز این رو بگم که این منابع میتونن تغییر کنن در طول زمان پس هرچه که در این مطلب بیان شده رو در مرداد ۱۴۰۰ معتبر بدونید و اگر مدتی بعد از انتشار این مطلب دارید مطالعهش میکنید، با جستوجو و پرسوجو در مورد این منابع، اطلاعات بهروزتر دریافت کنید.
Kaggle
وبسایت کگل، یک محیط تقریبا مشابه شبکههای اجتماعی برای دانشمندان داده و متخصصین هوش مصنوعی به حساب میاد. در این وبسایت شما میتونید مجموعه داده (Dataset) های خوبی رو پیدا کنید. همچنین، میتونید کارهایی که ملت روی اون دادهها انجام دادن رو در قالب Kaggle Kernel (به نوعی همون جوپیتر نوتبوک خودمون) ببینید و یا کارهای خودتون هم به اشتراک بذارید.
برای دسترسی به کگل، میتونید روی این لینک کلیک کنید.
Academic Torrents
این وبسایت هم وبسایت جالبیه (و به نوعی مرتبط با بخش بعدی). در واقع هر حرکت آکادمیکی که زده شده و اطلاعاتش هم همزمان منتشر کردند رو در خودش داره. چرا؟ چون جست و جو در محتوای آکادمیک نسبتا سخته و این وبسایت اون کار رو براتون راحت کرده. همچنین یک بخش خوبی برای مجموعهداده (لینک) هم در این وبسایت در نظر گرفته شده.
برای دسترسی به این وبسایت، میتونید از طریق این لینک اقدام کنید.
وبسایت دانشگاهها
همونطوری که در بخش قبلی گفتم، بسیاری از دانشگاهها (و در کل، فضاهای آکادمیک) تحقیقات زیادی انجام میدن و دادههای اون تحقیقات رو هم معمولا منتشر میکنن. چرا که یکی از اصول مطالعات آماری، اینه که دادهها به صورت شفاف منتشر بشن (شاید دلیلش اینه که بعدها، یکی بخواد خودش اون آزمایش و مطالعه رو تکرار کنه و …).
به همین خاطر، وبسایت دانشگاهها – چه ایرانی و چه خارجی – میتونه محل خوبی باشه برای مراجعه و پیدا کردن دادههای خوب برای مطالعه.
دیتاستهای متنباز شرکتها
بسیاری از شرکتهای بزرگ مثل گوگل، فیسبوک، آمازون و …، میان و حجم خوبی از دادههایی که قبلتر در تحقیقاتشون استفاده کردند رو به صورت اوپنسورس، منتشر میکنن. پیدا کردن این دیتاستها هم اصلا کار سختی نیست.
برای مثال، در این لینک میتونید دیتاستهای گوگل رو ببینید. یکی از نمونههایی که خود گوگل اینجا مطرح کرده، دیتاست مرتبط با بیماری کووید-۱۹ است. (لینک)
چرا این شرکتها، دیتاستها رو منتشر میکنن؟ باز هم میگم دقیقا به همون دلیلی که دانشگاهها منتشر میکنن. شاید افراد یا سازمانهایی باشن که بخوان تحقیقات و مطالعات رو برای خودشون تکرار کنند و یا نتیجه آزمایشات و … رو صحتسنجی کنند.
خزیدن (Crawling) صفحات وب
خب، بعضی وقتا هم دادهای که ما نیاز داریم، توسط شرکتها یا دانشگاهها منتشر نشده. پس در این حالت چه کار میکنیم؟ اگر داده مورد نظر، در اینترنت موجود باشه، میتونیم یک خزنده (Crawler) بسازیم و با اون کارمون رو پیش ببریم.
در بسیاری از زبانهای برنامهنویسی و چارچوبهاشون، ابزارهای بسیار خوبی برای کراول کردن صفحات وب وجود داره. یکی از بهترین نمونههاش میتونه BeautifulSoup در پایتون باشه. در مطالب بعدی، احتمالا با استفاده از این ابزار، یک خزنده برای وبسایتهای مختلف خواهیم نوشت.
دوربین، میکروفن، حرکت!
اگر دادههای مورد نیاز ما حتی به شکلی که بتونیم کراول کنیم موجود نبود چی؟ سادهست. ابزارهای ورودی خوبی برای کامپیوتر وجود داره که میتونه بهمون کمک کنه تا داده مورد نظر رو جمعآوری کنید.
گذشته از این، دوربین تلفنهای همراه، میتونه منبع خوبی باشه برای جمع آوری تصاویر(پروژههای بینایی ماشین و …)، میکروفنهای استودیویی برای دریافت صدا خوبن. اگر نیاز به دیتایی مثل گرما یا رطوبت نیاز دارید، طراحی مداری که این داده رو از محیط بخونه و روی دیتابیس خاصی ذخیره کنه کار سختی نیست.
جمعبندی
پروژههای هوش مصنوعی به ذات سخت نیستند. چیزی که اونها رو سخت میکنه، همین دیتای ورودی و تمیزکاری و مرتب کردنشه. بعضی وقتا دادههای ما کم هستند و ما مجبور خواهیم شد که Data augmentation انجام بدیم. بعضی وقتا ممکنه نویز به قدری زیاد باشه که اصلا مرحله جمعآوری دیتا رو مجبور بشیم دوباره از نو انجام بدیم و … .
خلاصه هدف از این مطلب این بود که اگر پا در این عرصه گذاشتید، بدونید همیشه جایی هست که بتونید بدون مشکل، دادههایی رو دریافت و در پروژهتون استفاده کنید و از بابت نویز و …، خیالتون تا حد خوبی راحت باشه.
در مطالب قبلی پیرامون مهندسی اجتماعی نوشتم. در اولین مطلب صرفا به این اشاره کردم که چیه و چرا مهمه، در مطلب دوم در مورد متد ماحیگیری نوشتم و در این مطلب، قراره دو روش دیگر مهندسی اجتماعی یعنی OSINT و همچنین خبرسازی رو با هم بررسی کنیم. اینجا، تقریبا میشه گفت که مباحث مهندسی اجتماعی تمام میشن و احتمالا در آینده جوانب دیگر امنیت سایبری رو با هم بررسی خواهیم کرد.
هوشمندی متنباز (OSINT)
همانطوری که در قسمت اول خدمت شما عرض کردم، ما در شبکههای اجتماعی و در کل در اینترنت خیلی از خودمون ردپا به جا میذاریم. هوشمندی متنباز یا Open Source Intelligence دقیقا همینجا به کار هکرها میاد. روش کلاهسفیدش به نظر میتونه بررسی عقاید و سلایق مردم برای تولید محصول باشه (مثلا خوانندهها به ما پول بدند که در سلیقه موسیقی مردم فضولی کنیم و براشون تحلیل ارائه بدیم) و روش کلاهسیاهش میتونه این باشه که دیتای جمعآوری شده رو بهونهای کنیم برای پروندهسازی و اخاذی از دیگران.
البته ما آدمای خوبی هستیم و چنین کاری نمیکنیم. ساختن پرونده هم به عهده مقامات امنیتی کشورها واگذار میکنیم چون اونها بهتر از ما بلدند و طبیعتا، راحتتر از ما میتونن چنین کاری کنند. اما اگر آدم بدی هستید هم به نظرم بهتره که برید تو اتاق و به کارای زشتتون فکر کنید جای این کارا 🙂
برای OSINT ابزارهای خوبی ساخته شده. در این پست من صرفا ابزارهایی که برای توییتر و اینستاگرام ساخته شدند رو یک بررسی ریز میکنم، اما اگر ابزار دیگری پیدا کردم احتمالا معرفی کنم. حواستون هم باشه استفاده از این ابزارها گرچه مانع قانونی نداره، اما اگر از دادههای به دست آمده برای کاری مثل اخاذی یا پروندهسازی استفاده کنید مسیر رو برای شکایت کردن افراد از خودتان باز خواهید کرد.
توییتر
چند وقت پیش، در توییتر بحثی به نام «ابر کلمات» داغ بود. افرادی که دسترسی به API توییتر داشتند، برای افراد این ابر کلمات رو میساختند. اما من از اونجایی که حوصله نداشتم با توییتر نامهنگاری کنم، دنبال ابزاری بودم که حداقل توییتهای حسابهای حفاظتنشده رو به سادگی بتونه استخراج کنه. اونجا بود که با ابزار twint آشنا شدم (لینک). ابزار twint یا twitter intelligence ابزاریه که به شما کمک میکنه به سادگی در توییتر بچرخید و مثلا توییتهای یک شخص رو استخراج کنید.
برای مثال، برای این که ۱۰۰ توییت آخر ریاست جمهوری آمریکا رو استخراج کنیم، کافیه دستور تویینت رو به این شکل اجرا کنیم:
twint -u potus --limit 100 -o potus.json --json
به این شکل، ما به سادگی به ۱۰۰ توییت آخر اون حساب کاربری دسترسی داریم.
البته میتونیم این دستور رو هی گسترش بدیم و ویژگیهایی مثل تاریخ، ساعت، مکان و … هم بهش اضافه کنیم. حالا این کجا به کارمون میاد؟ یه سناریوی خیلی ساده (که مربوط به بخش دوم همین مطلب هم میتونه بشه) رو در نظر بگیرید. مثلا قراره موز گران بشه. شما کافیه که twint رو به این شکل اجرا کنید:
twint -s "گرانی موز" --near Tehran --limit 1000
این هزار توییت آخری که مربوط به «گرانی موز» میشن رو برای ما لیست میکنه. میتونیم بفهمیم چه کسانی بهش دامن زدند و چه کسانی پیروی کورکورانه کردند و … . خلاصه که اتصال نقاط به یکدیگر خیلی راحتتر میشه.
اینستاگرام
برای اینستاگرام هم ابزارهایی وجود دارند که کمک کنند شما به سادگی بتونید در دیتایی که مردم به صورت حفاظتنشده (پابلیک یا عمومی) منتشر کردند بخزید و ببینید که دنیا دست کیه. OSINT در اینستاگرام، علاوه بر مقاصد خبیث (😂) میتونه به شدت بهتر برای مقاصد بازاریابی و تجاری استفاده بشه. چرا که بسیاری از مردم، در اینستاگرام به دنبال چیزایی که دوست دارند میگردند و خیلیها هم حتی خریداشون رو از طریق اینستاگرام انجام میدن.
البته، اینستاگرام الگوریتمهای عجیب و غریب زیاد داره و جدیدا APIش هم کمی سختگیر تر شده. ابزاری که برای اینستاگرام پیدا کردم، اسمش هست Osintgram (لینک) و این ابزار رو متاسفانه فرصت نشده که تست کنم هنوز. اما، یک ویدئوی خوب از کانال NetworkChuck براش پیدا کردم که میتونید اینجا ببینیدش.
ابزارهای دیگر؟
صد در صد هزاران ابزار دیگر برای OSINT وجود دارند. من فقط میخواستم که مفاهیم پایهش رو با هم بررسی کنیم و ببینیم که چی به چیه. در آینده، اگر ابزار خوبی برای OSINT پیدا کنم، حتما معرفی خواهم کرد چرا که لازمه بدونیم در دنیای اینترنت چطور میتونیم به سادگی تحت نظر باشیم. اونم نه تحت نظر افرادی که با تحت نظر گرفتن آدما، امنیتشون رو تامین میکنند، تحت نظر یه مشت دیوانه 🙂
خبرسازی
خبرسازی، یکی از راههای دیگر مهندسی اجتماعی، برای جا انداختن یک مفهوم یا یک ترس یا حتی طرفداری از شخصه. خبرسازیها، معمولا از طرف یک نفر نیستند بلکه از طرف گروهها انجام میشن. مثال کلاسیکش هم میتونه ماجرای فیسبوک و رباتهای روسی در جریان انتخابات امریکا باشه.حالا این خبرسازیها به چه شکل صورت میگیره؟ معمولا یک الگوریتم خاصی رو داره. به جهت این که مثالش کمی ملموستر باشه، از ترند «آهنربایی شدن بدن بعد دریافت واکسن» که تازگیها خیلی روش مانور داده شد استفاده میکنم.
مرحله اول: یک نفر به قصد شوخی در پلتفرمهای شوخی مثل تیکتاک، ویدئویی میذاره از این که اشیا فلزی بعد دریافت واکسن بهش میچسبن (لینک)
مرحله دوم: افرادی که میدونن این موضوع شوخیه، اون رو در شبکههای اجتماعی به نمایش میذارند.
مرحله سوم: اشخاصی که از ابتدا با موضوع واکسن مشکل داشتند، با زدن سر و ته (دقت کنید زدن سر و ته اینجا واقعا مهمه!) داستان، اون رو بازنشر میدن.
مرحله چهارم: توهمش در بسیاری از افراد به وجود میاد و یک سری خبر واقعیتر و غیرتیکتاکی ساخته میشه (لینک)
مرحله پایانی: افراد زیادی باور میکنند که چنین چیزی وجود داره …
حالا این خبر، از خبرهای میشه گفت شکبرانگیز بوده. اما در همان مثال «گرانی موز» هم میشه اینطور خبرسازی کرد. البته خبرسازی معمولا روشهای جلوگیری خوبی هم داره که در ادامه بهشون میپردازیم.
چطور بفهمیم که قربانی خبرسازی نشدیم؟
معمولا ما سواد رسانهای بالایی نداریم. چون کارمون رسانه نیست. به همین خاطره که به راحتی میتونیم قربانی خبرسازی و اخبار جعلی – بخصوص در محیط شبکههای اجتماعی – بشیم. اول از همه زمانهای بسیار قدیم یادمه که وبسایت درسنامه دورهای برای این کار داشت اما متاسفانه ظاهرا این وبسایت دیگر در دسترس نیست (و در ویکیپدیا هم توضیح درستی نیست ازش) اما خب میشه با یک سری راه ساده فهمید که داستان چیه.
بپرسید. اگر افرادی رو میشناسید که در اون حوزه فعالن حتما بپرسید.
بررسی کنید. با همین ابزارهای OSINT میتونید خط فکری و طرفداری افرادی که یک خبر رو پخش کردند پیدا کنید. این به شما در قضاوت بهتر کمک میکنه.
واکنشسنجی کنید. واکنش مردم در این موارد واقعا مهمه، ببینید که اکثریت چه واکنشی میتونن نشون بدن. عمدتا این واکنشها البته درست نیستند، اما میتونن سرنخهای خوبی به من و شما بدند.
در نهایت، از منابع خبری معتبر داخلی و خارجی استفاده کنید تا صحت خبر را بسنجید.
شاید این آخرین مطلب از سری اختصاصی «مهندسی اجتماعی» بود، اما باید یادمون باشه که همیشه این روشها یکسان نیستند و در طول زمان میتونن بهروز بشن. در واقع یادتون باشه، هر قفلی که ساخته بشه، یک قفلشکن هم براش پیشتر ساخته شده.
وظیفه ما، اینه که هم دیگر رو آگاه کنیم و به هم بگیم که چه چیزی ممکنه به ما در اینترنت آسیب بزنه یا در کل، ما رو در اینترنت عریانتر کنه. معرفی ابزارها و روشها، صرفا به این خاطره که شما بتونید خودتون رو بررسی کنید و ببینید که چقدر دیتا ازتون موجوده و اگر راضی نیستید به وجودش، حتما برای حذفشون اقدام کنید.
خلاصه که متشکرم از وقتی که برای خوندن این مطلب گذاشتید. امیدوارم مفید واقع شده باشه.
اینستاگرام یک شبکه اجتماعی بسیار خوب برای بازاریابی، ارائه محصول و در نهایت اشتراکگذاری تصاویریه که به شناخت بهتر شما یا برندتون کمک میکنه. قرار نبود چنین مطلبی بنویسم چون فکر میکردم خیلی از راههای تضمینی که در اینترنت وجود دارند، بعد مدتی ممکنه اسپم تشخیص داده بشن و خوب نباشن. اما خب، یکی از این راهها رو تستی رفتم و باید بگم که نتیجه گرفتم 🙂 در کمتر از ۲۴ ساعت دنبالکنندگان صفحهای که برای آزمایش ساخته بودم، به ۱۶ رسید.
از آنجایی که احتمالا این قضیه دغدغه شما هم هست، در این پست اون رو با شما به اشتراک میذارم که دنبالکنندگان صفحاتتون رو بتونید افزایش بدید.
ساخت صفحه
اولین قدم شما برای دریافت تعداد خوبی دنبالکننده باید ساخت صفحه باشه. ساخت صفحه، کاری نداره. به همین خاطر هم در اینجا راحت ازش گذر میکنیم و به راهاندازی نخستین صفحه میپردازیم.
تکمیل مشخصات
اولین قدم برای این که صفحه شما بتونه دنبالکننده دریافت کنه، اینه که مشخصاتش کامل باشه. در واقع شما به این موارد نیاز دارید:
تبدیل صفحه به صفحه Professional (در صورتی که صفحه واقعا قراره یک صفحه حرفهای و مرتبط با برند شما باشه)
تصویر نمایه
بیوگرافی
لینکهایی مثل شماره تماس و وبسایت هم اگر دارید قرار بدید بد نیست. چرا که موتورهای جستجو ممکنه از همونها بتونن افراد رو به شما برسونن.
قرار دادن پست
گرچه قرار دادن پست اجباری نیست، اما بهتره که برای صفحه تازه تاسیس خودتون حدود ۳ تا ۹ پست تهیه کرده باشید. احتمالا اگر صفحه شما مربوط به بیزنس شما، برند شخصی یا هنرتون باشه، متاعی که در صفحه قرار بدید در دسترستون هست و میتونید به سادگی این کار رو انجام بدید.
اگر پست آماده نداریم چی؟ مشکلی نداره. فقط نرخ دنبال شدن کمی میاد پایینتر و فکر کنم برای شروع اونقدرام بد نباشه. بهرحال قرار نیست ما مثل یک شخص نامدار یا اینفلوئنسر، دنبالکننده و … جذب کنیم.
به دنبالِ دنبالکننده گشتن …
خب شما دنبالکنندگان خودتون رو میخواید درست؟ اینجا جاییه که من فرمولش رو به شما میگم. اول از همه ببینیم که دنبالکننده (فالوئر/Follower) کیه؟ شخصیه که بخاطر محتوایی که شما تولید میکنید میاد و پیج رو دنبال میکنه. حالا وقتی محتوا کمه یا محتوا نداریم چطور میتونیم دنبالکننده جذب کنیم؟ برای پاسخ به این سوال، من سه احتمال زیر رو براتون توضیح میدم:
دنبالکننده ارگانیک: دنبالکننده ارگانیک، یعنی یک شخص یا بیزنس حقیقی پشت حساب کاربریش نشسته. بهترین نوع دنبالکننده بلاشک، همینه. چرا؟ چون میدونید که افرادی هستند که برای محتوای شما فالوتون کردند و با تقلب کردن یک نرمافزار شخص ثالث، به دنبالکنندگان شما اضافه نشدند.
دنبالکننده جعلی: حسابهای جعلی که خودتون میسازید، رباتهایی که دنبالکننده رو در زمان کم به حساب شما اضافه میکنن و … از این دست هستند. این دنبالکنندهها فعالیتی ندارند و فقط عدد و رقم الکی به شما اضافه میکنن. داشتن تعداد زیاد دنبالکننده بدون فعالیت و تعامل مفید، به هیچ دردی نمیخوره.
دنبالکننده ارگانیکِ جعلی: شاید باورتون نشه اما این مورد هم وجود داره. افرادی هستند که صفحاتی رو میسازند، تعداد خوبی دنبالکننده جذب میکنند و بعد صفحه رو به قیمتهایی که معمولا پایین هم نیستند، میفروشند. این فالوئرها، خوبن. اما مفید نیستند. اکثرا آدمهایین که برای دنبال کردن دیگران، هزینهای دریافت کردند یا در سیستم «داداشم فالو شه» خیلی معرفت به خرج دادند. به اینستاگرامشون سر نمیزنن و براشون مهم نیست در فلان صفحه چی بگذره و معمولا هر چندروز یک بار اینستاگرام رو باز میکنند، یه لایکی میزنن و میرن. اینها نه بدن و نه خوب، برای رقمسازی نیمچه ارگانیک، میتونن کمک باشن.
حالا تا اینجا آمدیم، بیایید فرمول تضمینی دریافت نخستین دنبالکنندهها رو بررسی کنیم 🙂 این که چطوری به دست میان و ما باید چه کار کنیم. حقیقتش، کار سختی نیست و حوصله میخواد. شاید هم بد نباشه که این وسط، اتوماسیونی صورت بگیره (احتمالا آموزش نوشتن ابزار اتوماسیونش هم به زودی منتشر کنم 😁).
مرحله اول: پیدا کردن تیکهای آبی
اول از همه، ما نیاز به یک سری صفحه داریم که اصطلاحا «تیک آبی» خوردند یا به عبارت بهتر، وریفای شدند. وریفای بودن صفحات، به این معناست که یک درجه خوبی از شهرت رو دارند. همین امر باعث میشه که دنبالکنندگان زیادی هم داشته باشند. گذشته از اون، بسیاری از دنبالکنندگان اون صفحات هم دنبال افرادی میگردن که در حوزههای مشابه فعالن. پس بازی، یک بازی برد-برد خواهد بود. حالا مرحله مرحله این کارها رو انجام بدیم؟
مشخص کردن حوزه کاری: در یک سناریو خیالی، فرض کنیم صفحه ما در حوزه موسیقی فعاله و موسیقیش محدود به ایران نیست. اولین کاری که باید بکنیم چیه؟ این که افرادی رو پیدا کنیم که در حوزه موسیقی فعالن و شهرت بینالملل دارند. مثلا گروهی مثل Metallica (طبیعتا با توجه به سبک کاری خودمون و سلیقمون میتونه عوض بشه) یک گروه فوق مشهوره و چند میلیون دنبالکننده داره. یک لیست از این افراد تهیه میکنیم.
دنبال کردن افراد لیست: الان کار ما راحت شده. افراد درون لیست رو یک به یک دنبال میکنم.
دنبال کردن دنبالکنندگان و دنبالشوندگان: این مورد بسیار مهمه، در بین دنبالکنندگان و دنبالشوندگان همون تیکهای آبی، باید دنبال باقی تیکهای آبی باشید! مثلا در یک گروه موسیقی ممکنه اعضاش هم خودشون تیک آبی داشته باشند. پس بهتره که فالوشون کنیم 🙂
تا اینجای بحث خوبه؟ نه؟ کار راحتی نیست ولی سخت هم نیست. به شما ایده کلی میده که این روش چطور کار میکنه. حالا باید بریم سراغ مرحله دوم 🙂
مرحله دوم: تکرار این عملیات به مدت چند روز
تیکهای آبی رو فالو کردید؟ بسیار هم عالیه. زاکربرگ به شما افتخار میکنه. حالا نوبت اینه که همه رو آنفالو کنیم (و خیر، شما مسخره پدر اینستاگرام نیستید و این روشیه که ما پیش میگیریم) و دوباره فالو کنیم.
این حرکت رو بهتره ۲ الی ۳ روز ادامه بدیم. احتمالا روز دوم متوجه خواهید شد که یک عده شما رو فالو کردند و معمولا عددش هم خوبه (برای من حدود ۱۶ نفر در یک روز بود که واقعا رقم خوبیه!). به این شیوه میشه در حدود ۳ روز، نزدیک به پنجاه نفر به دنبالکنندگان اضافه کرد. برای شروع، خوبه؛ نیست؟
و مرحله بعد چیه؟ مرحلهای دیگه در کار نیست. همین فرمون برید جلو تا به رقم دلخواه در دنبالکنندگان خودتون برسید. اما یادتون نره که اینستاگرام مثل هر پلتفرم دیگری، یک پلتفرم تولید محتواست و نه پلتفرم فالو/آنفالو بازی. در همین حینی که دارید فالو و آنفالو میکنید یادتون باشه که محتوای مناسب هم تولید کنید که ورودیتون از هشتگها و پستاتون هم خوب باشه.
نکات مهم در این روش
خب، شاید بد نباشه نکات مهمی رو بهتون گوشزد کنم که صفحهتون از بین نره. چرا که خیلی از ماها صفحه رو صرفا برای برند خودمون میسازیم و اگر از دست بره، بازسازیش کار حضرت فیل میشه. به همین خاطر به این نکات توجه کنید:
بیش از ۱۰۰ صفحه رو در روز دنبال نکنید. اینستاگرام ممکنه رفتار فالو-آنفالو رو به شکل اسپم و یا «فعالیت مشکوک» تشخیص بده و حساب شما رو ببنده.
سعی کنید این روش رو بیش از حد ادامه ندید. ممکنه در آینده این روش دیگه جواب نباشه و شما طبیعتا سرد میشید نسبت به ادامه فعالیت.
سعی کنید در صفحاتی که دنبال میکنید لایک بزنید، کامنت بذارید و … . این هم به اون صفحه و هم به اینستاگرام نشون میده که شما واقعا فعالیت ارگانیک دارید و فعالیتتون رباتی نیست.
در نهایت، بگم که روشهای افزایش فالوئر زیادند اما تضمینی نیستند. یک زمانی، صرف فالو کردن افراد در اینستاگرام کافی بود. یادمه که در هشتگها میشد چرخید و تعداد زیادی رو فالو کرد و اونها اصطلاحا «بک» میدادند. اما الان این روش کاملا منسوخ شده. روشی هم که در این مطلب پوشش دادم احتمالا به زودی منسوخ میشه پس تا معتبره، سعی کنید ازش استفاده کنید و حالشو ببرید 😁
جمعبندی
اول از همه، باید بگم که این مطلب برای من یک استراحت در میان مطالبی که در مورد مهندسی اجتماعی مینویسم بود. دوم این که، خودم تجربه استفاده از این روش رو داشتم وگرنه من معمولا آدمی نیستم که چنین مطالبی رو بنویسم و نشر بدم. در نهایت، بگم که این مطلب آموزش «پولدار شدن» به شما نیست! پس چیه؟ آموزشیه برای دریافت تعداد خوبی مخاطب که بتونید هنرتون یا کسب و کارتون رو به دنیا معرفی کنید. همونطوری که گفتم بعدها میتونه روشهای بهتری هم براش ارائه بشه. پس اگر مثل اینفلوئنسرها دیده نشدید هم نگران نباشید. همیشه روش خوبی براش هست 🙂
و در آخر، ممنونم از این بابت که وقت گذاشتید و مطلب من رو خوندید. شما هم اگر روش خوبی برای اینستاگرام مارکتینگ دارید، ممنون میشم با من به اشتراک بذارید 🙂
شاید الان با دیدن عنوان پست به خودتون گفتید که «ای بابا اینم که بیسوات از آب دراومد»، اما باید بگم نه، اشتباه نیست 🙂 عبارت «ماحیگیری» به نوعی بومیشده واژه Phishing به حساب میاد. فیشینگ یا ساخت صفحه جعلی، در واقع یک روش رایج برای انجام عملیات مهندسی اجتماعی و دزدیدن اطلاعات شماست.
در این مطلب، در مورد فیشینگ و راهکارهای جلوگیری ازش قراره صحبت کنیم. پس آماده باشید که بریم سراغ اصل مطلب 🙂
فیشینگ و راههای مبارزه با آن
سناریوی یک حمله فیشینگ
فرض کنید که یک ظهر تابستانی داغه، شما تازه از سر کار برگشتید و قصد دارید خونهتون رو کمی خلوت کنید. اولین چیزی که به ذهنتون میرسه چیه؟ اینه که وسایلی که به نظرتون اضافی هستند رو بفروشید. فرض کنیم که شما قراره یک میز یا یک صندلی رو بفروشید. پس گوشیتون رو برمیدارید، از وسیله مورد نظر تعدادی عکس تهیه میکنید، وارد اپلیکیشن دیوار میشید و بعد از اون یک آگهی فروش درست میکنید.
همهچی خوبه، نه؟ 🙂 من میگم نه! چون بعد از این که شما آگهیتون رو منتشر میکنید و تایید میشه، یک پیام دریافت میکنید. در پیام ذکر میشه که مبلغ کمی، مثلا در حد هزار یا دو هزار تومان باید پرداخت کنید وگرنه آگهی حذف میشه. اینجا دو قسمت رو باید در نظر بگیریم که بعدا بهش برسیم:
هزار یا دو هزار تومان یا حتی ده هزار تومان پول زیادی نیست. معمولا راحت پرداختش میکنیم.
ما از این که آگهیمون حذف بشه ترس داریم. چرا؟ چون احتمالا به پول نیاز داشتیم که یه وسیله اضافی رو برای فروش قرار دادیم.
حالا شما روی لینک – بیتوجه به مشخصاتش – کلیک میکنید. وارد اون لینک میشید و میبینید که یک درگاه پرداخت کاملا درسته. اطلاعات کارتتون رو وارد میکنید و بعد از چند روز متوجه میشید که کارتتون خالی شده.
پینوشت : عمده این بحث برمیگرده به زمانی پیش از رمز پویا. گرچه الان هم برای رمز پویا راههای زیادی هست که بتونن ازتون بقاپنش.
نقاط ضعف ما در حملات فیشینگ
سناریوی بالا رو خوندید؟ دو مورد نقطه ضعف رو نوشتم. شاید یکیش صرفا بازی روان باشه اما عمدتا نقاط ضعف ما در این حملات (و در کل مهندسی اجتماعی) هدف قرار گرفته. در ادامه نقاط ضعفی که ممکنه برای شما دردسر بشه یا ماحیگیرها ازش استفاده کنند رو ذکر میکنیم:
ترس عقبماندگی یا FOMO – به این شکل که ممکنه به شکل فروش رمزارز، فروش بلیت بختآزمایی و …، ازتون اطلاعاتتون رو بگیرند و جای دیگر استفاده کنند.
ترس از پروندهسازی – این به نظر ممکنه احمقانه بیاد، اما حقیقتیه که وجود داره. چطور؟ ممکنه شما در معرض شکایتهای متعدد بوده باشید (مثلا شرکت ورشکستهای دارید و تعداد طلبکارانتون زیاده و …) و به این شکل ماحیگیر میتونه با استفاده از این ترس شما، با صفحه جعلی از سامانههایی که برای پلیس یا قوه قضاییه طراحی شدند، اطلاعات خصوصیای مثل سابقه کیفری شما رو علنی کنه.
ترس از دست دادن – در کیسهای خاصی مثل فروش روی دیوار، ترس از دست دادن به شدت میتونه قوی عمل کنه. با این ایده که شما پول لازم دارید و برای حذف نشدن آگهی هرکاری ممکنه بکنید.
لو دادن اطلاعات – این مورد کمی حساستره. در مکالمات روزمره، اینترکشنهای شبکههای اجتماعی و … مراقبتر باشید تا خدای نکرده، اطلاعاتی که بتونن محل زندگی، محل کار و … شما رو مشخص کنن رو اساسی لو ندید. چون همین اینها، میتونن باعث بشن که شما راحتتر طعمه فیشینگ بشید.
ما الان نقاط ضعف خودمون رو میدونیم. پس چطور میتونیم جلوی این حملات رو بگیریم؟ حقیقت تلخی هست و اون هم این که نمیتونیم. هکر، کلاهبردار، دزد و … همیشه هستند. همیشه هم مشغول کارند. کاری که ما میتونیم بکنیم کاری مثل ماسک زدن مقابل کروناست. این مثال ماسک رو چرا مدام به کار میبرم؟ چون میدونیم که ماسک هم صد در صد ما رو مقابل بیماری مصون نمیکنه (از شما چه پنهون که حتی واکسنها هم نمیکنن، فقط خطر بیماری رو کاهش میدن) ولی شانس ابتلا رو میاره پایین. پس ما هم شانس این که به تور ماحیگیرها بیفتیم رو میاریم پایین.
ماسک مناسب برای ویروس فیشینگ
در این بخش از مطلب، صرفا راهکارهایی که باعث شدن خودم تا الان کمتر مورد این حملات قرار بگیرم رو در اختیارتون میذارم. طبیعتا این راهکارها میتونن در طول زمان کمتر شن یا کلا دیگه معتبر نباشن. اما برای امروز (۱۷ خرداد ۱۴۰۰) کاملا کار میکنند.
چک کردن HTTPS محلهایی که دیتا وارد میکنیم (این راهکار الان هم اعتبار زیادی نداره، چرا که ماحیگیر میتونه به سادگی بره سراغ این که از Let’s encrypt یک گواهی SSL بگیره)
چک کردن آدرس وبسایت با آدرسهای معتبر (مثلا gmail صفحه ورودش mail.google.com/login خواهد بود، چیزی جز این احتمالا حقیقی نیست. البته دامین گوگل بسته به منطقه و VPN شما میتونه متفاوت باشه)
چک کردن اسامی، آدرسها و وبسایتها در اینترنت و درآوردن سوابقشون (حتی دایرکتوریهایی برای این قضایا ساخته شدند)
وارد کردن اطلاعات غلط اگر به درگاه یا صفحه لاگین مشکوکیم (چرا که معمولا وقتی اطلاعات رو غلط وارد کنیم، صفحه به صفحه واقعی ریدایرکت میشه، اینطوری به ماحیگیرا هم آدرس غلط دادیم)
اطلاعرسانی در باب این تیپ دزدیها به بقیه 🙂
در کل، اگر حواسمون نباشه احتمال این که سرمون کلاه بره خیلی خیلی زیاده. حواستون باشه که با چک کردن یک سری موارد ساده، به سادگی میتونیم از شر دزد و … در امان باشیم.
جمعبندی
در نهایت، ازتون بابت این که مطلب رو خوندید تشکر میکنم. دوم، امیدوارم این سلسله مطالب به دردتون خورده باشه. سوم، شما چه راهکاری برای جلوگیری از فیشینگ دارید؟ 🙂
در دنیایی زندگی میکنیم که متاسفانه یا خوشبختانه، عمده اطلاعات ما روی اینترنت هستند. در توییتر اسم و عکسمون روی پروفایله و از روزمرگیهای زندگیمون مینویسیم. در اینستاگرام لحظات غم و شادی خودمون رو به اشتراک میذاریم. در ساندکلاد صدای خودمون یا سازمون رو به رخ دیگران میکشیم. در لینکدین اطلاعات کار و تحصیل و … رو قرار دادیم. بسیار هم خوب، اما این دادهها و اطلاعات، آیا ممکن نیست علیه خودمون استفاده شه؟
جواب به سوال بالا «بله» است. احتمالا شما هم از پدر و مادرتون زیاد شنیدید که «ملت گرگن» و باید گفت که بله، اینترنت پر از گرگهاست. گرگهای اینترنت اما متفاوت از گرگهای اون بیرونن. گرگهای اون بیرون، معمولا تا وقتی سمتشون نرید گاز نمیگیرن، معمولا تا وقتی همکارشون نشید زیرابتون رو نمیزنن و … . اما گرگهای اینترنت چی؟ گرگهای اینترنت از هیچ فرصتی برای کسب اطلاعات در مورد شما و اذیت و آزار شما از اون طریق، دریغ نخواهند کرد. در این پست، قراره که با فرایند «مهندسی اجتماعی» آشنا بشیم و بعد یک سری راهکار برای مقابله باهاش ارائه کنیم.
اتصال نقاط، سادهترین روش مهندسی اجتماعی
چند وقت پیش، در مورد امنیت بیتکوین و معاملاتش داشتم مطالعه میکردم. یک نکته جالبی برخوردم که بد نیست شما هم در موردش بدونید. شخصی که مطلب رو نوشته بود (متاسفانه با کامپیوتر قدیمیتری مطلب رو خوندم و در هیستوری مرورگرم نیافتمش، وگرنه پیوند میدادم) اینطور بیان کرده بود که:
درسته که بلاکها و تراکنشها رمز شدند و ما روی حریم خصوصی این نوع ارز حساب ویژه باز کردیم، اما یادتون باشه که مردم نقطهها رو به هم وصل میکنن.
حالا، بیاییم ببینیم که این «نقطه»ها چین؟ ما چطور میتونیم به هم وصلشون کنیم؟ چرا اتصال نقاط مهمه و … . اول از همه، بیایید صرفا چندتا نقطه رو ببینیم:
سلام، من فلانی هستم.
من سال ۹۳ رفتم دانشگاه.
من کامپیوتر خوندم.
در یک بحثی مرتبط با یکی از دانشگاههای مطرح کشور (بیایید بگیم دانشگاه X)، من ورود کردم و از استادی، نقل قول کردم یا از استادی بد گفتم.
در لینکدین من، مشخصه که کجا کار میکنم اما محل تحصیلم رو مشخص نکردم.
از آب و هوای یک منطقه خاص در ایران تعریف و تمجید کردم.
حالا این دادهها رو داریم. چطور میتونیم ازش به اطلاعات بدرد بخوری برسیم؟ خب کاری نداره. بیایید در وصل کردن نقطهها با من همراه شید و ببینید چقدر ترسناکه 🙂
وقتی گفتم «من فلانی هستم» احتمالا به اسم شناسنامهایم، لقبم، اسم مستعارم یا یکی تو این مایهها اشاره کردم. وقتی گفتم سال ۹۳ رفتم دانشگاه، شخص میتونه حدس بزنه که من از اکثریتی بودم که ۱۸ سالگی رفتند دانشگاه پس احتمالا متولد ۷۵ باشم، اما بعضی وقتا (برای آقایان) دانشگاه رفتن بعد از خدمت سربازی اتفاق میافته، پس اینجا بهتره که در نظر بگیرید که رنج تاریخ تولد بین ۷۳ تا ۷۵ بوده.
در مورد رشته تحصیلیم صحبت کردم. البته رشته تحصیلی گهگاهی از محتوای تولیدشده روی اینترنت هم قابل حدسه، گاهی هم از بحثهایی که افراد با دیگران میکنن و به اسم اساتید یا دروس خاصی اشاره میکنن. مثلا اگر در بحثی اشاره به «الکترونیک دیجیتال» شده باشه، احتمال خیلی خوبی داره که شخص «مهندسی کامپیوتر گرایش سختافزار» رو در دانشگاه خونده باشه. پس به این شکل، میتونیم رشته تحصیلی فرد هم دربیاریم.
بعد از این، میرسیم به بحث در مورد محل تحصیل. در لینکدین شخص، نتونستیم چیزی پیدا کنیم. اما مثلا اومده و گفته «استاد چاکراهی در دانشگاه X از اون عوضیاس که دومیش خودشه». این که شخصی انقدر دقیق یک استاد رو بشناسه، با لفظ استاد صداش کنه و یا اشارهای به سابقه آکادمیکش کنه، نشان از اینه که اون شخص احتمالا در محل تدریس اون استاد تحصیل کرده. به این شکل اطلاعات بسیار دقیق تحصیلی هم داریم. یک جمعبندی از این سه پاراگراف بکنم؟ من الان میدونم «فلانی، متولد فلان سال، فلان رشته رو در فلان دانشگاه خونده».
و اما در مورد آخرین نقطه. صحبت در مورد مکانها، معمولا توسط کسی صورت میگیره که اشرافی به اون مکان داره. پس چه اتفاقاتی ممکنه بیفته؟ سادهترینش اینه که حدس هکر به سمت این بره که شما ساکن اونجایید. ممکنه مشخص نشه که ساکن اونجایید، اما شما گوشی رو دست شخص دادید که روی منطقهای خاص اشراف دارید و اونجا رو به خوبی میشناسید. پس در اون منطقه قطعا آمد و شدی دارید.
حالا اینا به کنار، چرا باید روی «اتصال نقطهها» انقدر حساس باشیم؟ به فرض که طرف دونست شما چهکارهاید و کجا زندگی میکنید، خب تهش که چی؟ در ادامه بررسی میکنیم.
اتصال نقطههای مختلف به هم، این شرایط رو فراهم میکنه
در موارد حساس (مثل امنیتی شدن جو کشورها، حساس شدن مسئولین یک شرکت یا سازمان روی موضوعی خاص و … ) میتونه به شناسایی راحت شما کمک کنه.
شما رو در معرض آسیبهای روانی (باجخواهی، پروندهسازی و …) قرار بده.
احتمال آسیب فیزیکی رو ببره بالا.
این رو در نظر داشته باشید. حالا بیایید بریم سراغ راههایی که مهندسی اجتماعی میتونه حتی راحتتر هم باشه. من بهش میگم «مهندسی اجتماعی تعاملی».
مهندسی اجتماعی تعاملی
در مهندسی اجتماعی تعاملی، هکر اتفاقا آدم ناامن و زاغسیاهچوبزنی نیست! بلکه دقیقا یکیه که با شما تعامل داره. این تعامل به روشهای زیر میتونه انجام شه:
ساخت حساب کاربری و کسب شهرت در شبکههای اجتماعی
ساخت حساب کاربری با نام و مشخصات جعلی در شبکههای اجتماعی و پیامرسانها و ایجاد روابط دوستی با دیگران
ساخت صفحات جعلی از وبسایتهای خبری، صفحه ورود شبکههای اجتماعی، فرمهای تماس و … .
انتشار اخبار جعلی
در خواست کمکهای نقدی (در قالب ارزهای رایج، رمزارز و …)
حالا اینها هرکدوم چطور کار میکنن؟ بسیار هم خوب. بیایید در ادامه بررسیشون کنیم.
ساخت حسابکاربری و کسب شهرت در شبکههای اجتماعی
خواهناخواه بسیاری از حرفهایی که ما میزنیم، میتونه تاثیر خوبی در «بالا آمدن» و مشهور شدن اشخاص دیگر داشته باشه. کافیه که شخصی که دیتا میخواد با ترفندهایی مثل «فالو کنید بک میدم» یا «منشن بده بگو اسم عمه کوچیکت چند تا ر داره» و …، یک پایگاه خوبی از آدمها رو میسازند. حالا ممکنه فکر کنید که «مشکلش چیه؟» به ذات مشکلی نداره. هر انسانی نیاز طبیعی به توجه و روابط انسانی داره و این حق طبیعیشه. حتی خیلی از این اینترکشنها جالب و جذابن و به نظرم شرکت درشون میتونه خوشگذرانی کوتاهمدت خوبی باشه.
مشکل اصلی، زمانی رخ میده که این روش، میشه وسیلهای برای اقدامات بعدی. مثل چی؟ مثل انتشار خبرهای جعلی و یا کلاهبرداری و سوءاستفادههای متعدد از افراد. همین الان از افرادی که شناختهشدگی خوبی در دنیا دارند (مثل خوانندهها، بازیگران، فوتبالیستها و …) خبرهایی مثل آزار جنسی یا ایجاد مزاحمت کم نیست! فلذا بهتره که حواسمون جمع باشه که چه کسانی رو مشهور میکنیم و چرا.
ساخت حساب کاربری با نام و مشخصات جعلی در شبکههای اجتماعی و پیامرسانها و ایجاد روابط دوستی با دیگران
شاید با خودتون بگید «عه این هم که مسالهای نداره، طرف نخواسته با هویت واقعیش فعال باشه». درست میفرمایید. این که هویت ساختگی داشته باشیم هم یک «حق» برای ماست (شاید جالب باشه بدونید که یکی از هجمههایی که علیه فیسبوک هست همینه! که چرا کاربران رو فورس میکنه هویت واقعی خودشون رو بذارن روی اکانتهاشون) ولی نکات مهمتری هم وجود داره. در اینجا یک کیسی رو مثال میزنم.
فرض کنید شخصی هست که حساسیت گروه خاصی رو برانگیخته. شخص A و گروه G میگیم برای راحتی کار. حالا گروه G یک پلنی چیده که به شکلی، بخواد شخص A رو از مسیر خودش کنار بزنه. اینها میتونن یک «کارمند سابق» و یک «شرکت» باشن (خلاصه فکر نکنید همیشه ماجرا، ماجرای سیاسی و … است). پس گروه G چه میکنه؟ یکی رو مامور میکنه تا اکانتی بسازه و با اطرافیان A دوست شه. به این شکل میتونه طی دوستی با روشهای مختلفی، اطلاعات به دست بیاره.
روشهای کسب اطلاعات هم میتونن به خودی خود جالب باشن. در ادامه بعضیاشون رو لیست میکنم :
سوال در مورد تواناییهای متفاوت شخص (در قالب تعریف و تمجید، تعجب، غیبت و …)
سوال در مورد تیپ شخصیتی فرد.
اعلام این که به شخص A علاقمند شده و نمیتونه پا پیش بذاره (بخصوص اگر A خانم باشه)
بدگویی از شخص برای سنجش نوع روابط و این که دیگران در مورد اون شخص چی میگن
دیدید، این فقط چهار حالتیه که به ذهن من میرسه. این حالات میتونه بسیار بسیار بیش از این قضیه باشه. فلذا حواستون باشه دفعه بعدی که پشت سر همکارتون حرف زدید، خدای نکرده به شخصی که باهاش خصومت داره دیتا ندید 😁
انتشار اخبار جعلی
اخبار جعلی هم میتونن در دامنه مهندسی اجتماعی قرار بگیرند! در واقع جمع کردن حجم خوبی از واکنشهای مردم به خودی خود گرچه میتونه یک آزمایش باشه (که معمولا این آزمایشها از قبل اطلاع داده میشن) اما به طور کل، برای پخش یک ایده خاص یا جمع کردن حجم خوبی از ریاکشنها، استفاده میشه.
بخصوص در زمانهایی که به اتفاقات خاصی مثل انتخابات نزدیک هستیم، گستره این اخبار به شدت بزرگ میشه و خیلی راحت میتونن در نتایج بسیاری از تصمیمات جمعی تاثیرگذار باشن.
درخواست کمکهای نقدی
در مورد این روش، بعدا به تفصیل خواهم نوشت. فقط حواستون باشه که خیلی از افرادی که در اینترنت به دنبال جمعآوری کمکهای نقدی هستند، هدفشون «کار خیر» نیست. بلکه صرفا به جیب زدن حجم خوبی پوله 🙂
ساخت صفحات جعلی
در مورد این یکی هم، به زودی خواهم نوشت. فقط عبارت «ماحی گیری» یا Phishing رو در ذهنتون داشته باشید.
چطور از مهندسی اجتماعی در امان بمونیم؟
خب بذارید راحت بهتون بگم آدم فضول، آدم زاغسیاهچوبزن، عین ویروس کروناست. نمیشه ازش در رفت، فقط میشه ریسکش رو کاهش داد. در ادامه، در مورد کاهش ریسکش کمی راهکار بهتون ارائه میدم 🙂
تا حد امکان سعی کنید دادههای خودتون رو منتشر نکنید. اگر هم کردید، سعی کنید وسطش نویز بدید.
ارسال عکس و صدا برای غریبهها کار خوبی نیست. سعی کنید کمتر سراغش برید.
به خیلی از موارد واکنشی نشون ندید. داغ شدن بعضی موارد (نمونه سادهش دنگ کافه!) میتونه به سادگی باعث بشه که شما دادههای زیادی از خودتون، محل زندگی و کارتون، روابطتون و … لو بدید.
از افرادی که به نظر ناامن میان دوری کنید!
به هرپیامی نیاز نیست پاسخ درست بدید.
برای واکنش دادن به اخبار و یا بازنشر اونها، منابع خبری معتبر داخلی و خارجی رو بررسی کنید. حسابهای کاربری تاییدشده رو هم چک کنید و ببینید که کی، چی گفته. یافتن حقیقت به اون سادگیها هم نیست چرا که بسیاری از موارد خبرهای کذب، توسط همون اشخاص نامدار هم میتونه نشر داده بشه.
در بحثهایی که حس میکنید ممکنه دردسرساز بشه براتون، شرکت نکنید.
از افرادی که مدعی هکری اجتماعی و مهندسی اجتماعی و … هستند دور شید. اینها ممکنه به خوبی بقیه هکرها نباشند، اما قطعا یه نقطهای برای آزار شما پیدا میکنند.
در نهایت، آرزو دارم که هیچوقت طعمه گرگهای اینترنت نشید. این مطلب مطلب کاملی نیست و دست کم دو یا سه پست دیگه فقط در همین مورد خواهم نوشت. اما دوست دارم پیش از نگارش مطالب دیگر، نظرات شما رو پیرامون این موضوعات بدونم.
پس از مدت طولانی، با یک پست دیگر برگشتم و این بار قراره با هم احراز هویت JWT رو در ریلز بررسی کنیم. اول از همه، لازمه بدونیم JWT چیه؟ چرا نیازش داریم؟ اصلا چرا احراز هویت و هزاران چرای دیگر که احتمالا الان در سر شما هستند. بعدش یک پروژه خیلی کوچولو ایجاد میکنیم و با هم براش احراز هویت رو پیادهسازی میکنیم 🙂
احراز هویت JWT چیه و چرا بهش نیاز داریم؟
اول از همه این سوال بنیادیتر رو پاسخ بدیم که «چرا احراز هویت نیاز داریم؟» و بعد بریم سراغ احراز هویت JWT که قراره در این مطلب در موردش مفصل حرف بزنیم.
ما به احراز هویت نیاز داریم چون همیشه بخشی از دادههای ما، خصوصی هستند. گذشته از اون، احراز هویت میتونه اجازه CRUD رو به شما بده، نه؟ فکر کنید اپی دارید که هرکسی میتونه روش بخونه و بنویسه. ممکنه خوندن چیزی باشه که برای «همه» مناسب باشه اما «نوشتن» اینطور نیست. بخصوص که نوشتن خودش به قسمتهایی مثل حذف و بروزرسانی هم شکسته شده.
پس ما به احراز هویت نیاز داریم که هر ننهقمری (😂) نتونه از API ما استفاده کنه. بلکه کاربرانی که ثبتنام کردند و دسترسی درستی به سرویس دارند، بتونن استفاده کنن. این قضیه در API های تجاری (یا Business facing) خودشون رو بیشتر و بهتر نشون میدن.
حالا سوال مهمتر …
احراز هویت JWT چیه؟
در اپهای قدیمی (مثل همین وردپرس)، احراز هویت توسط cookie ها انجام میشه. به چه صورتی؟ به این صورت که وقتی نام کاربری و گذرواژه وارد میکنیم، نرمافزار فضایی رو در مرورگر به خودش اختصاص میده و یک سری اطلاعات رو با خودش جابجا میکنه. اما در ReST API ها این قضیه رو نداریم. در واقع نمیتونیم به کوکیها اعتماد کنیم. پس چه میکنیم؟ اینجا لازمه جز یوزرنیم(که معمولا میتونه عمومی باشه) و پسورد (که میتونه راحت لو بره) میاییم و یک «توکن» هم تعریف میکنیم. این توکن، میتونه ثابت یا متغیر باشه. یعنی چی؟ یعنی میتونه به ازای هربار ورود تغییر کنه، میتونه سر زمان مشخصی هم منقضی بشه.
حالا توکن چیه؟ توکن به صورت کلی، در کازینوها معادل پولیه که شما در بازیها قرار میدید، در واقع مجوز حضور شما در اون کازینو، کلاب و … است. حتی به رمزارزهایی که بر مبنای دیگر رمزارزها ساخته میشن هم سکه نمیگن بلکه میگن توکن. شما فرض کنید که مثلا ۱۰۰ دلار میدید و پنج تا سکه با آرم اون کازینوی خاص دریافت میکنید. اگر در بازی برنده بشید یا ببازید، باید توکنهاتون رو تحویل بدید یا بگیرید.
حالا در احراز هویت JWT هم، ما به ازای کاربرمون یک توکن در نظر میگیریم. این توکن، معمولا یک رشته طولانیه که انسان نمیتونه بخوندش. نتیجتا خیلی از اطلاعات ما به صورت ایمنتر میتونن رد و بدل بشن (طبیعیه که مواردی مثل SSL داشتن و الگوریتمهایی که در ساخت توکن داشتیم هم مهمن). ضمن این که نامکاربری، ایمیل، رمزعبور و .. هم به همین سادگیا نمیتونن خونده بشن.
پس ما میآییم و یک دیتابیسی از توکنها در کنار دیتابیسی از یوزرها میسازیم (البته درستترش، جدوله!) و به ازای هر یوزر معمولا دوتا توکن در اون دیتابیس قرار میدیم. یکیش رو بهش میگیم «توکن دسترسی» یا Access Token و یکی رو میگیم «توکن بازنشانی» یا Refresh Token. توکن دسترسی، معمولا یک تاریخ انقضایی داره و بعد از اون با استفاده از توکن بازنشانی، میتونیم یکی جدید بگیریم. اما در آموزش امروز، صرفا میخوایم توکن دسترسی رو به دست بیاریم.
احراز هویت JWT به این شکل کار میکنه
خب، الان که تقریبا همهچی رو میدونیم، بریم برای پیادهسازی.
پیادهسازی یک اپلیکیشن ریلز با JWT
خب در قدم اول، باید یک اپ ایجاد کنیم. این اپ رو به این شکل ایجاد میکنیم:
rails new devise-jwt --api
خب توضیح واضحات:
قسمت rails که واضحا فراخوانی نرمافزار rails در ترمینال ماست.
قسمت new در خواست برای ایجاد یک اپ جدیده.
قسمت devise-jwt اسم پروژه ماست. حالا چرا؟ چون قراره از یک لایبرری با همین اسم استفاده کنیم. بنابراین، پروژه رو اینطوری اسم گذاشتیم.
در قسمت آخر هم، به ریلز گفتیم که ما تو رو بخاطر API هات دوست داریم. ویو نیاز نیست.
بعد از چند ثانیه (و بسته به سرعت اینترنت دقیقه) اپ ما ساخته میشه. بعد لازمه که مرحله مرحله کارهایی رو انجام بدیم.
نصب لایبرریهای مورد نیاز
خب، اول از همه با ویرایشگر متنی مورد علاقمون فایل Gemfile رو باز میکنیم و این خطوط رو بهش اضافه میکنیم :
gem 'devise'
gem 'devise-jwt'
gem 'rack-cors'
بعد از این که این خطوط رو اضافه کردیم، دستور زیر رو اجرا میکنیم:
bundle
این دستور چه کار میکنه؟ میاد و تمام لایبرریهای مورد نظر شما رو به صورت ایزوله در یک دایرکتوری، نصب میکنه. به این شکل شما میتونید به سادگی بدون رسیدن آسیب به باقی لایبرریهای روبی نصب شده روی سرور یا حتی کامپیوتر خودتون، ایدههاتون رو تست کنید.
لازم به ذکره که بعد از اجرای این دستور فایل Gemfile.lock بهروز میشه، این فایل حالا چه کار میکنه؟ این فایل حواسش به همهچی هست. در واقع، ورژن روبی، ورژن ریلز، لایبرریهای مورد نیاز و ورژنینگشون و … رو همه رو این فایل داره کنترل میکنه.
بعد از انجام مراحل فوق، کافیه این دستور هم اجرا کنیم:
rails g devise:install
این دستور چه میکنه؟ این دستور هم برای ما فایلهای devise رو در جای درستش قرار میده.
آشنایی با devise
برای احراز هویت در هر سیستمی ما دو راه داریم:
نوشتن سیستم احراز هویت از بیخ
استفاده از کتابخانههای موجود
در مورد روش «از بیخ»، ما معمولا این کار رو انجام نمیدیم. چرا؟ چون معمولا اونقدر خوب نیستیم که بتونیم امنیت سیستم رو به خوبی تامین کنیم. در مورد دوم، در هر فرمورک و زبانی، کتابخانههایی ساخته شدند که کمک میکنن ما بتونیم با اضافه کردنشون به پروژه خودمون، بخش احراز هویت رو هندل کنیم. برای ریلز devise ساخته شده. این لایبرری، یک لایبرری مبتنی بر cookie برای احراز هویت وباپهاست.
بعد از همهگیر شدن ReST API ها، لایبرری devise-jwt هم نوشته شد. این لایبرری، ابزاریه که به من و شما کمک میکنه بتونیم احراز هویت JWT رو به پروژهمون اضافه کنیم. در واقع هر سه لایبرری که به پروژه اضافه کردیم، کارشون همینه که JWT رو برای ما راحت کنند.
هندل کردن CORS
در این مطلب قصد ندارم در مورد CORS حرف بزنم، چون قبلتر ازش حرف زدم (و میتونید اینجا بخونید). اینجا ما صرفا قصدمون اینه که بیاییم و این مشکل رو حل کنیم. چطوری؟ خب این فایل:
config/initializers/cors.rb
رو با ویرایشگر متنی مورد علاقهمون باز میکنیم، و محتواش رو به این شکل تغییر میدیم:
Rails.application.config.middleware.insert_before 0, Rack::Cors do
allow do
origins '*'
resource '*',
headers: :any,
methods: [:get, :post, :put, :patch, :delete, :options, :head]
end
end
توجه کنید که این قسمت معمولا به صورت کامنتشده در کد هست، فقط کافیه آنکامنتش کنید و نیاز نیست که کلا این مورد رو کپی پیست کنید.
ساخت مدل و کنترلرهای مورد نیاز برای کاربر
یکی از خوبیهای devise اینه که به شکل scaffold گونهای، میتونه به ما کمک کنه که کاربر و سیستم کنترلش رو بسازیم. برای ساخت مدل کاربر فقط کافیه که این دستور رو اجرا کنیم:
rails g devise User
به این شکل میفهمه که باید یک مدل، مطابق مدل User ولی با مشخصات devise برامون بسازه. بعدش هم کافیه این دستور رو اجرا کنیم:
rails db:migrate
که جدولای مرتبط برامون در دیتابیس ساخته بشن.
حالا که خیالمون از بابت این قضایا راحت شد چی؟ هیچی. دو تا کنترلر هم میسازیم به این شکل:
rails g controller users/sessions
rails g controller users/registrations
بعد از این میشه گفت که کار ما اینجا تمام شده و باید بریم یه چیزایی رو ادیت کنیم 🙂
ویرایش مدل یوزر
بعد از این که کارهای بالا رو انجام دادیم، کافیه که بریم سراغ مدل یوزرمون و به این شکل ادیتش کنیم:
class User < ApplicationRecord
devise :database_authenticatable,
:jwt_authenticatable,
:registerable,
jwt_revocation_strategy: JwtDenylist
end
حالا این کار برای چیه؟ برای اینه که ما یک جدول دیگر به اسم JWT Deny List در نظر میگیریم و توکنهای منقضیشده رو درونش قرار میدیم. به اون شکل وقتی توکنی منقضی بشه، میتونیم به کاربر خطا نشون بدیم یا از توسعهدهندههای فرانت تیم بخوایم که وقتی اون خطا رو دیدن، کاربر رو لاگ اوت کنن. خلاصه که راه برای رسیدن به نتیجه مطلوب زیاده. بگذریم، بعد از این، در پوشه مدلها لازمه که یک فایل به اسم jwt_denylist.rb ایجاد کنیم و این محتوا رو درونش قرار بدیم:
class JwtDenylist < ApplicationRecord
include Devise::JWT::RevocationStrategies::Denylist
self.table_name = 'jwt_denylist'
end
بعد نیاز داریم که برای این قضیه یک مایگرشن اضافه کنیم:
rails g migration CreateJwtDenylist
سپس، فایل مایگرشن که معمولا در آدرس:
db/migrate
قرار داره رو باز میکنیم و محتواش رو به این شکل تغییر میدیم:
class CreateJwtDenylist < ActiveRecord::Migration[6.1]
def change
create_table :jwt_denylist do |t|
t.string :jti, null: false
t.datetime :exp, null: false
end
add_index :jwt_denylist, :jti
end
end
و بعد یک دور مایگرشنها رو اجرا میکنیم:
rails db:migrate
تا اینجا مطلب طولانی شد؟ ایرادی نداره. بریم یک قهوه بزنیم به بدن و برگردیم 🙂
کنترلر Session
امیدوارم که کافئین به قدر کافی مودتون رو بالا آورده باشه 🙂 حالا وقتشه که بریم و کنترلر session رو درست کنیم. نیازی نیست واقعا کار خاصی کنیم. تنها کاری که نیازه بکنیم اینه که کنترلری که ساختیم رو باز کنیم و این موارد رو درش کپی کنیم:
class Users::SessionsController < Devise::SessionsController
respond_to :json
private
def respond_with(resource, _opts = {})
render json: { message: 'You are logged in.' }, status: :ok
end
def respond_to_on_destroy
log_out_success && return if current_user
log_out_failure
end
def log_out_success
render json: { message: "You are logged out." }, status: :ok
end
def log_out_failure
render json: { message: "Hmm nothing happened."}, status: :unauthorized
end
end
نکته مهم، اگر هنگام ساخت کنترلر، جای users از چیز دیگری استفاده کردید باید Users رو در کد بالا به اون تغییر بدید. اگر هم کلا چیزی نذاشتید، کل قسمت Users:: رو ازش حذف کنید.
کنترلر Registration
خب عین همون بخش قبلی، شما کافیه کنترلر registrations رو باز کنید و این کد رو درونش کپی کنید:
class Users::RegistrationsController < Devise::RegistrationsController
respond_to :json
private
def respond_with(resource, _opts = {})
register_success && return if resource.persisted?
register_failed
end
def register_success
render json: { message: 'Signed up sucessfully.' }
end
def register_failed
render json: { message: "Something went wrong." }
end
end
تنظیمات نهایی devise
خب اول در ترمینال (یا cmd) این دستور رو اجرا کنید:
rake secret
و یک کد طولانی و مسخره بهتون میده 😁 اون رو در فایل:
config/initializers/devise.rb
در آخر فایل به این شکل کپی کنید:
config.jwt do |jwt|
jwt.secret = rake_secret_output
end
نکته بسیار مهم اینجا چیه؟ این که حواستون باشه این صرفا یک پروژه تسته و برای محیط پروداکشن اصلا جالب نیست که سیکرتها و توکنها، هاردکد باشن. برای اون زمان میتونید از ENV استفاده کنید.
مسیرها
خب، الان که تقریبا همهچی آرومه و ما چقدر خوشحالیم، کافیه که بیاییم و فایل routes.rb رو هم به این شکل ویرایش کنیم:
Rails.application.routes.draw do
devise_for :users,
controllers: {
sessions: 'users/sessions',
registrations: 'users/registrations'
}
end
خب پس چی میمونه که انجام ندادیم؟ یک سری آزمایش ساده 🙂
ساخت کاربر
خب الان کافیه بعد اجرای سرور ریلز (مطابق آموزشهای قبلی)، این دستور رو اجرا کنیم:
که اینها سرایند (Header) های ما هستند. در این قسمت، هرچی جلوی Authorization قرار داره توکن ماست. و میتونیم ازش استفاده کنیم.
بخش بعدی هم اینه :
{"message":"You are logged in."}
که صرفا به ما میگه ورودمون موفقیتآمیز بوده.
فکر کنم این مطلب، آخرین مطلبی بود که در مورد بیسیکهای روبیآنریلز مینوشتم. احتمالا در آینده نهچندان دور، همه اینها رو با هم به یک سری آموزش ویدئویی تبدیل کنم و از طریق آپارات یا یوتوب منتشرشون کنم.
طبیعتا یک قسمتهایی از آموزش در این مطلب پوشش داده نشده، سعی میکنم در آینده یک یا دو پست تکمیلی هم ارائه کنم که همه این قضایا به خوبی پوشش داده بشه (یا این که کلا در بخش ویدئویی در خدمتتون باشم).
به صورت کلی، دوست دارم بدونم نظر شما در مورد این تیپ آموزشها چیه؟ آیا ادامهشون بدم یا خیر؟ و این که آیا پایهش هستید که بحث فرانتند رو هم شروع کنیم یا روی همین بکند باقی بمونیم و اول یه پروژه کامل رو بکندش رو بزنیم و بعد بریم سراغ فرانت؟ 🙂
در آخر هم بابت وقتی که گذاشتید و مطلب رو خوندید ازتون متشکرم.
در پست قبلی با هم یک REST API نوشتیم که یک نمونه از مدل «پست» رو میتونست ایجاد کنه، بروز کنه، نمایش بده و نابود کنه.
در این پست هم قصد دارم که کار مشابهی کنم، منتها این بار تیم محصول به ما یک سناریوی جدید داده. از ما خواستند که این بار، کامنت هم به پستها اضافه کنیم و بتونیم با استفاده از API برای هرپستی، یک کامنت هم ایجاد کنیم. پس وقت رو غنیمت میشماریم و میریم سروقت پروژه (پوشهها و ساختار عینا مثل پست قبلیه و هیچ تغییری در اون رخ نداده).
ساخت مدل برای کامنت
بیاییم ببینیم تیم محصول برای ما چی طراحی کرده. این عزیزان در نظر دارند که هر کامنت صرفا یک «متن بدنه» داشته باشه و بیشتر از اون نیاز نداشتند. کار ما اینه که حالا مدلی طراحی کنیم که علاوه بر اون، به پستها هم ربط داشتهباشه. چطوری این کار رو میتونیم بکنیم؟
کافیه دستور زیر رو اجرا کنیم و مدلش رو بسازیم:
rails generate model Comment body:text post_id:integer
خب حالا میریم به پوشه :
app/models
و اول post.rb رو به این شکل ویرایش میکنیم:
class Post < ApplicationRecord
has_many :comments
end
و سپس comment.rb رو به این شکل ویرایش میکنیم:
class Comment < ApplicationRecord
belongs_to :post
end
حالا این خطوط چی میگن؟ ما در پایگاه داده چندین نوع رابطه داریم. توضیح این روابط به صورت مفصل باشه برای یک پست دیگه. اما اینجا بیاید در نظر بگیرید که طراحی محصول به شکلی بوده که «هر پست میتونه بیشمار کامنت داشته باشه و هر کامنت متعلق به فقط و تنها فقط یک پسته». این نوع رابطه اسمش هست «یک به چند» یا بهتر بگم «یک به خیلی» و به قول خارجیها One to many.
حالا که از این قضیه خبر داریم و پست رو هم ساختیم تعلل نمیکنیم. میریم سراغ ساخت کنترلر مربوطه. اینجا کنترلر به ما کمک میکنه که بتونیم به سادگی یک کامنت رو روی پست بسازیم و مدیریت کنیم. در مورد سناریوی کنترل کامنت هم این بار کمی سادهتر میگیریم. در ادامه این مورد رو با هم بررسی خواهیم کرد.
ساخت کنترلر کامنت
اول کنترلر کامنت رو به این شکل ایجاد میکنیم:
rails generate controller api/v1/comments
و سپس در فایل:
config/routes.rb
این تغییر ریز رو ایجاد میکنیم :
Rails.application.routes.draw do
namespace :api do
namespace :v1 do
resources :post do
resources :comments
end
end
end
# For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html
end
و بعد میریم سروقت کنترلر 🙂 اما قبل از اون بیاید یه چیزی رو بررسی کنیم. این روابط رو! این روابط چطوری تعیین شدند؟ و چرا مهمند. پس در ترمینالمون تایپ میکنیم:
rails c
این دستور، به ما یک «کنسول ریلز» میده. کنسول به ما کمک میکنه که ایدهها رو در یک لول قبل از مرورگر و درخواستهای HTTP بررسی کنیم. در اسکرینشات زیر از ترمینال من، میبینید که چطوری یکی از پستها رو تست کردم و دیدم که آیا روابطش با کامنتها درسته یا خیر.
خب حالا بیاییم کنترلر رو بنویسیم. قبل از اون، من یک کامنت دستی در کنسول به این شکل میسازم:
c = Comment.new(:body => "This is a comment", :post_id => 1)
c.save
و کنسول رو میبندم. میریم سراغ کنترلرمون. همونطور که گفتم اینجا یه سری چیزا نیستن. مثلا show اینجا نیازی نیست باشه ولی index نیاز هست. پس میریم سراغ این که این موارد رو در کنترلر لحاظ کنیم. خب با توجه به این توضیحات، ما یک متد index به این شکل نیاز داریم:
def index
@post = Post.find(params[:post_id])
render json: @post.comments
end
همونطور که دیدید، اینجا تنها چیزی که نیازه بررسی بشه post_id ماست. درخواستی که به سمت سرور میفرستیم هم به این شکله:
curl -X GET -i http://localhost:3000/api/v1/post/1/comments
حالا وقتشه که بتونیم یک کامنت جدید ایجاد کنیم. برای ساخت کامنت جدید هم کافیه که به این شکل، متد create رو بنویسیم:
def create
@comment = Comment.new(:body => params[:comment][:body], :post_id => params[:post_id])
if @comment.save
render json: {:status => "success", :comment => @comment}
end
end
و نمونه درخواستی که براش میفرستیم هم به این شکل:
curl -X POST -H 'Content-Type: application/json' -i http://localhost:3000/api/v1/post/1/comments --data '{
"body":"This is another comment"
}'
حالا یک سوال مهم ممکنه برای شما پیش بیاد و اون هم اینه که :
چرا پارامترهای ارسالی فرق دارند؟
دلیلش خیلی سادهست. ریلز اول میاد پارامترهای درون URL رو مستقیم میخونه، بعد میاد سراغ Request Body که در واقع اگر سلسله مراتبی (مثل یک فایل YAML) بهش نگاه کنیم این شکلی میشه:
- post_id: 1
- comment:
- body: "This is another comment"
در واقع برای خودش یک Resource space در نظر میگیره و body رو از اون میخونه. به همین خاطره که یکی زیرمجموعه comment و دیگری مستقیما post_id میشه.
باقی متدها چی؟
معمولا کامنتها قابل ادیت و حذف و … نیستند. ما هم به جهت سادگی این ماجرا رو براشون پیادهسازی نمیکنیم تا بعدا چه پیش آید 🙂
جمعبندی دو قسمت اخیر
خب در این دوقسمت ما خیلی چیزا یاد گرفتیم که فهرستوار بررسی میکنیم :
چطور ریلز نصب کنیم.
چطور یک پروژه ریلز جدید ایجاد کنیم.
چطور یک منطق تجاری (Business Logic) رو درک کنیم
چطور مدلهای مورد نظر رو بسازیم
چطور API بسازیم و تست کنیم.
این موارد بسیار مهمن و فکر کنم بعد خوندن این دو قسمت حداقلهای ساخت یک API رو یاد گرفتید. بعد از این چه چیزهایی لازمه که یاد بگیریم؟ این دیگه بستگی به خودتون داره. شاید در موردش مطلبی بنویسم اما فکر کنم این آخرین مطلبیه که انقدر مستقیم داره به نوشتن و ساختن API اشاره میکنه.
در مطالب بعدی، میخواهیم بریم سراغ یک سری مفهوم و پیادهسازی دیگر. احتمال قوی هم بریم سراغ فرانتند و ببینیم که در دنیای فرانتند چه خبره. پس منتظر باشید که فصل جدیدی از مطالب فنی در راهه 🙂
در آخر، از شما بابت وقتی که برای خوندن این مطلب گذاشتید هم کمال تشکر رو دارم.
پس از مدتی دست کشیدن از بلاگ نوشتن، به دنیای نویسندگی فنی برگشتم و قراره که امروز با هم یاد بگیریم چطور یک Rest API رو با روبی آن ریلز بسازیم. چرا روبی آن ریلز؟ دو تا دلیل داره. یکی این که چون من بلدمش و دلیل دوم این که منبع فارسی خوب براش به شدت کمه (کما این که برنامهنویس خوب ریلز کم نداریم در ایران).
در این پست قراره چیا یاد بگیریم؟ اول این که Rest چیه. بعدش با ریلز یه پروژه جدید ایجاد میکنیم، بعدش هم یک سناریوی ریزی که در این قسمت تا بخش خوبیش رو پیش میبریم. در قسمت بعدی هم پروژه رو تموم میکنیم و میریم که داشته باشیم فرانتند رو 🙂
تعریف Rest
واژه REST مخفف Representational State Transfer و به معنای «انتقال بازنمودی حالت» است. یعنی چی؟ یعنی ساده و مختصر و مفیدش اینه که شما هرچی که دارید رو بدون تغییر در حالاتش، به کاربر منتقل میکنید. یک تعریف بهترش هم اینه که همه چی به شکل یک لینک اینترنتی و خروجی قابل فهم برای مرورگر (و البته بهتر بگم، پروتکل HTTP) دربیاد.
رست، مزایای خاص خودش هم داره. اما بزرگترین مزیتش اینه که همهجا یکیه! یعنی اینطوری نیست که روی وبسایت من یه شکل باشه و روی یک وبسایت دیگه یه شکل دیگه. همهجا میتونید با دانشی که از HTTP و ابزارهایی که برای ارسال و دریافت درخواست HTTP دارید، باهاش کار کنید. ابزاری که در این پست باهاش کار میکنیم چیزی نیست جز curl دوست داشتنی. یک ابزار خطفرمانی در یونیکس که سالیان ساله برای هر بده بستانی با HTTP داره استفاده میشه.
نصب و راهاندازی روبی، ریلز و نود جی اس!
نصب کردن این موارد حقیقتا چیزی نیست که بخوام در این مطلب بهشون اشاره کنم، فقط یک سرنخ کوتاه میدم و شما خودتون دنبالش کنید.
همونطور که از اسم فرمورک مورد نظر پیداست، یک چارچوب توسعه روی زبان روبی محسوب میشه. حالا چطوری روبی رو نصب کنیم؟ یک راه نسبتا بدی هست که از مخازن توزیع یا brew نصب کنیم، یک راه بهتر هم استفاده از RVM میتونه باشه. شخصا همیشه از RVM استفاده میکنم، و راضی هم هستم. چون بهتون اجازه میده که چندین و چند نسخه روبی نصب داشته باشید.
برای نصب RVM از وبسایتش (لینک) استفاده کنید. این ابزار روی لینوکس و مک به راحتی نصب میشه. برای نصب روی ویندوز هم من از همین ابزار به کمک WSL استفاده کرده بودم و نتیجه، رضایت بخش بود. بعد از نصب این بزرگوار مطابق راهنماهاش، یک نسخه روبی (پیشنهاد من ۲.۷.۲ که این مطلب با استناد به استانداردهاش نوشته شده) نصب کنید. بعد از نصب روبی، این دو دستور رو اجرا کنید که ریلز و متعلقات نصب بشن:
gem install bundle
gem install rails
نصب ریلز یکمی طولانیه. میتونید این زمان رو صرف نوشیدن یک فنجان قهوه کنید 🙂 این طولانی بودن هم ربط زیادی به اینترنت نداره، چون روی بستههای خاصی مثل sass یکم درجا میزنه چون نیاز داره یه چیزایی رو کامپایل کنه.
بعد از این، شما با مراجعه به وبسایت نود جی اس (لینک) و yarn (لینک) میتونید اینها رو هم متناسب با سیستمعامل خودتون نصب کنید. حالا همه چی آمادهست که پروژهمون رو بزنیم 🙂
آغاز پروژه
سناریو
خب بیاید فرض کنیم که یک شرکتی قراره یه سرویس وبلاگدهی مشابه مدیوم یا ویرگول ارائه کنه. در حال حاضر هیچی ازمون نخواسته جز :
امکان ارسال پست از طریق API
امکان ارسال نظر روی پست از طریق API
و خب در حال حاضر احراز هویت و … براشون مهم نیست چون میخوان ببینن که MVP کار میکنه یا نه؟! و ما هم از خداخواسته قبول کردیم این رو براشون پیاده کنیم. اما این همه ماجرا نیست. این دو مورد، باید یک سری ویژگی هم داشته باشن. این ویژگیها رو طراح محصول باید درآورده باشه. فرض کنیم که طراح محصول اینا رو درآورده و فعلا برای «پست» به ما یک سری ویژگی داده :
عنوان یا title : یک رشته کرکتری
عنوان کوتاه یا slug : یک رشته کرکتری که با – از هم جدا میشه، یک رشته رندم هم تهش میچسبه که منحصر به فرد بودنش رو تعیین کنه (چسبیدن رشته رندم رو از فرانت هندل کنید)
بدنه یا body : متن اصلی.
خب، با این ویژگیها از ما میخوان که پست رو پیاده کنیم تا ویژگیهای کامنت رو بهمون بدن 🙂
ساخت پروژه جدید
ساخت پروژه جدید در ریلز بسیار سادهست. شما فقط کافیه که در پوشهای (مثلا من روی کامپیوتر یه پوشه دارم به اسم playground که پروژههای شخصیم توشن) که میخواید پروژه اونجا باشه، این دستور رو اجرا کنید:
rails new api-tutorial --api
اینجا چی کار میکنیم؟ rails که مشخصه، داره rails رو فراخوانی میکنه. new میگه یک پروژه جدید میخوام. قسمت بعدی، اسم پروژه و طبیعتا اسم پوشه پروژهست. در نهایت بخش مهم همون api عه. این داره به ریلز میگه که viewها و کلا مسخرهبازیای فرانتی رو بعدا و جدا انجام میدم. فعلا مسخرهبازی بکندی میخوام فقط 😁
حالا با اجرای دستور زیر، میریم به داخل پوشه پروژهمون:
cd api-tutorial
ساخت مدل جدید برای پست
همونطور که از مطلب MVC (لینک) میدونیم، مدل تعیین میکنه که یک موجودیت در دیتابیس به چه شکل قرار بگیره. خب، الان کاری که ما باید بکنیم چیه؟ اینه که دستور زیر رو اجرا کنیم و بگیم که چی میخوایم:
rails generate model Post title:string slug:string body:text
خب، در اینجا دقیقا همون چیزی که طراح محصول خواسته رو داریم پیادهسازی میکنیم. خب، الان در پوشه:
app/models
یک فایل به اسم post.rb ساخته شده که توش تقریبا هیچی نیست. و فعلا به اون فایل، کاری نداریم (تو قسمت دوم در مورد این فایل صحبت خواهیم کرد).
الان فقط لازمه که به دیتابیس بفهمونیم که ما یک جدول جدید برای پستها نیاز داریم. برای اون کار، دستور زیر رو اجرا میکنیم:
rails db:migrate
این کار برای ما جدول و روابطش رو میسازه.
ساخت کنترلر برای پست
خب، ما نیاز داریم که عملیات CRUD روی پست انجام بدیم. چرا؟
هر پست نیاز داره ایجاد بشه. پستی که ایجاد نشه پستیه که قطعا ایجاد نشده 😐
هر پست نیازمند اینه که به کاربر نمایش داده شه. قرار نیست مخزنالاسرار بسازیم که!
هر پست نیاز داره که ویرایش بشه. فرض کنید یه جا تو پست نوشتیم «خورش کرفس بهترین غذای دنیاست». خب معلومه که باید «خورش کرفس» رو به «قرمه سبزی» تغییر بدیم.
و هر پست باید قابل حذف شدن باشه. در مورد حذف نرم و سخت بعدا صحبت خواهیم کرد. اما فرض رو روی destroy یا همون «حذف سخت» میذاریم. چون طراح محصول هنوز اطلاعات بیشتری بهمون نداده.
خب، الان که این رو یاد گرفتیم چی کار میکنیم؟ این دستور رو اجرا میکنیم:
rails generate controller api/v1/post index show create update destroy
بعدش فایل :
app/controllers/api/v1/post_controller.rb
رو باز کنید. با چنین صحنهای روبرو خواهید شد:
class Api::V1::PostController < ApplicationController
def index
end
def show
end
def create
end
def update
end
def destroy
end
end
خب اول از new شروع میکنیم! از حرف C ! اما قبلش باید یک تغییر کوچکی در این فایل بدیم :
class Api::V1::PostController < ApplicationController
def index
end
def show
end
def new
end
def update
end
def destroy
end
private
def post_params
params.require(:post).permit(:title, :slug, :body)
end
end
متد post_params چی کار میکنه؟ این متد میاد فقط مواردی که نیازن رو validate میکنه و نمیذاره پارامتر بیشتر و یا اشتباهی به endpoint مربوطه پاس بدیم. خب، الان متد new رو به این شکل تغییر میدیم:
def new
@post = Post.new(post_params)
if @post.save
render json: {:status => "success", :content => @post}
else
render error: {:status => "fail"}
end
end
خب یک مزیت دیگر استفاده از post_params هم همینه، بدون دردسر میتونیم همه پارامترها رو پاس بدیم به متدهامون. حالا، بهتر اینه که این متد رو تست هم بکنیم نه؟ پس این دستور رو وارد میکنیم:
rails server
این دستور، سرور ریلز رو ران میکنه و به ما اجازه میده که برنامه خودمون رو آزمایش کنیم.
اما الان بهمون ارور میده. پس چی کار کنیم؟ هیچی. این فایل :
config/routes.rb
رو باز میکنیم و به این شکل درش میاریم:
Rails.application.routes.draw do
namespace :api do
namespace :v1 do
resources :post
end
end
# For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html
end
و حالا دوباره تست میکنیم. چطوری؟ به این شکل:
curl -X POST -H 'Content-Type: application/json' -i http://localhost:3000/api/v1/post --data '{
"title":"Hello, World",
"slug":"hello-world-abcd1234",
"body":"Hello, world! this is a simple test for my app"
}'
و خروجیای که میده به این شکله:
{
"status": "success",
"content": {
"id": 1,
"title": "Hello, World",
"slug": "hello-world-abcd1234",
"body": "Hello, world! this is a simple test for my app",
"created_at": "2021-03-28T17:44:16.608Z",
"updated_at": "2021-03-28T17:44:16.608Z"
}
}
حالا وقتشه که بریم سراغ R یعنی Retrieve/Restore. یعنی نمایش پستها و پست به صورت تکی. کافیه index و show رو یکم دستخوش تغییر کنیم:
def index
@posts = Post.all
render json: @posts
end
def show
@post = Post.find(params[:id])
render json: @post
end
و الان با ارسال چنین دستوری:
curl -X GET -i http://localhost:3000/api/v1/post/1
میتونیم پستهامون رو ببینیم.
حالا بیایم برای ویرایش هم چارهای بیاندیشیم 🙂 پس متد آپدیت هم به این شکل بهروز میکنیم:
def update
@post = Post.find(params[:id])
if @post
@post.update(post_params)
end
end
خب، اینجا چرا else نگذاشتم؟ چون اگر پست موجود نباشه (موجودیتش با if چک میشه) خود ریلز به ما ارور مناسب (معمولا ۴۰۴) رو نشون میده.
من در سیستم خودم، یک پست با آیدی ۲ دارم که قرار بود آپدیت بشه. الان اون رو با این دستور آپدیت میکنم:
خب، در نهایت فایل post_controller.rb ما به این شکل در اومده:
class Api::V1::PostController < ApplicationController
def index
@posts = Post.all
render json: @posts
end
def show
@post = Post.find(params[:id])
render json: @post
end
def create
@post = Post.new(post_params)
if @post.save
render json: {:status => "success", :content => @post}
else
render error: {:status => "fail"}
end
end
def update
@post = Post.find(params[:id])
if @post
@post.update(post_params)
end
end
def destroy
@post = Post.find(params[:id])
if @post
@post.destroy
render json: {:status => "success", :post_id => @post.id }
end
end
private
def post_params
params.require(:post).permit(:title, :slug, :body)
end
end
کل چیزی که در این قسمت نوشتم، برای درک عملکرد API کافیه. از شما هم میخوام که همین سناریو رو برای خودتون، یک دور به صورت کاملا دستی پیاده کنید و سعی کنید درش خلاقیت به خرج بدید. تجربیاتتون هم در بخش نظرات با من به اشتراک بذارید 🙂
قسمت بعدی، چی یاد میگیریم؟
در قسمت بعدی، کاری میکنیم کارستان. یاد میگیریم که در مدلها روابطشون رو تعیین کنیم. بعد مدلی میسازیم که به این مدل وابستهست. در نهایت هم به همین شکل، کنترلرش رو میسازیم و پروژه رو تحویل کارفرمای عصبانی میدیم 🙂
از این که وقت گذاشتید و این پست رو خوندید، واقعا ممنونم. هر یک ویویی که این پستها میخوره، برای من شدیدا ارزشمنده.
در پست قبلی، بررسی کردیم که اصلا MVC چیه و به چه کار میاد و یکم هم مثال ازش در روبی آن ریلز دیدیم. در این پست، قصد دارم مزایا و معایبش رو بگم و بگم که روبی آن ریلز، چه راهحلی برای مشکلاتش پیشنهاد میکنه.
باز هم لازمه که سلب ادعا کنم که این مطلب مطلقا آموزش روبی آن ریلز نیست و شما اگر میخواید روبی آن ریلز یاد بگیرید، میتونید تا پست بعدی منتظر باشید 😁
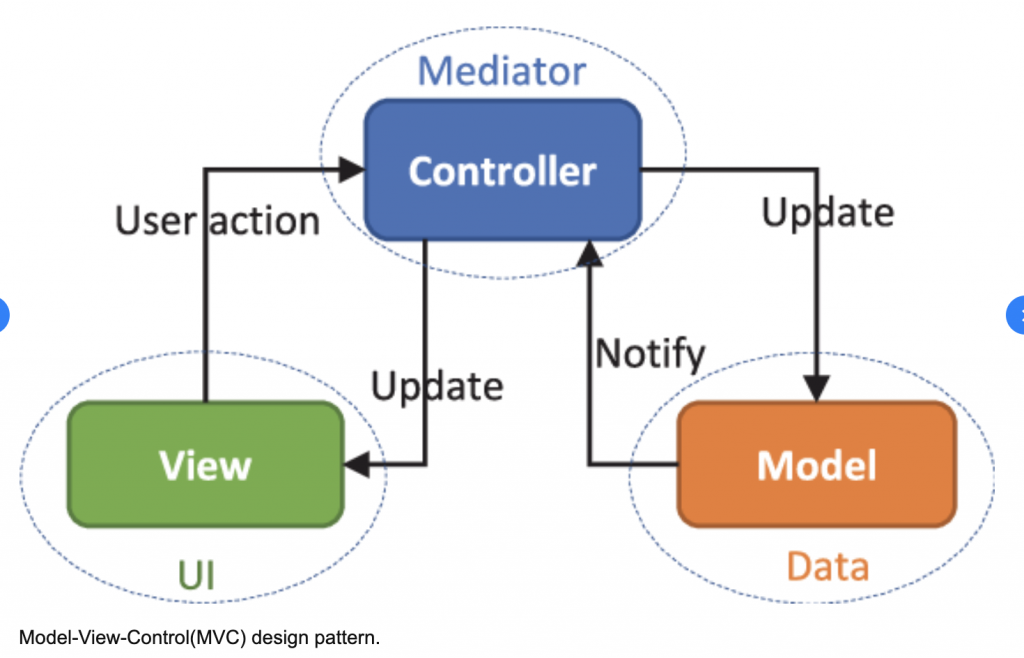
مروری بر کلیت MVC
از پست قبلی، این دید رو داریم که MVC در واقع یک روش تبدیل کردن موجودیتهای محصول به یک سری مدل، کنترل ارتباطاتشون با هم و با دنیای بیرون با یک سری کنترلر و نمایششون به صورت ویوئه (متفاوتتر از قبلی شد، نه؟ چون صرفا بیانم رو در تعریفش عوض کردم). اما حرفی از مزایای و معایبش نزدم.
عمدهترین دلیلم برای ادامه ندادن، این بود که مطلب قبلی زمان زیادی از من گرفت و حتی مجبور به ریبوت کردن لپتاپم میانه راه شدم. خود مطلب هم شدیدا طولانی بود و مطمئن بودم از یک حدی طولانیتر میشد، دیگه کسی اون رو نمیخوند.
حالا که تعاریف رو با هم بررسی کردیم، بریم سراغ اصل مطلب 🙂
مزایا و معایب معماری MVC
مزایا
تسریع فرایند پیادهسازی : همونطوری که در پست قبلی دیدید، اکثریت قریب به اتفاق چارچوبهای توسعه که با این معماری کار میکنند، ابزارهایی برای تولید و تست موجودیتها در اختیار شما میذارن. این به خودی خود موجب تسریع فرایند پیادهسازی میشه. در مورد توسعه هم این قضیه میتونه تا حدی صادق باشه، البته توسعه رو در بخش معایب بررسی میکنیم.
تسهیل فرایند کار گروهی : در یک بیزنس، معمولا بیش از یک نیرو روی محصول نهایی – چه در پیادهسازی چه در توسعه – کار میکنه. این معماری به توسعهدهندهها کمک میکنه بهتر بتونن محصول رو درک کنن. بخصوص اگر قرار باشه هر شخص روی یه بخشی کار کنه و پیادهش کنه.
تسهیل فرایند بهروزرسانی : طبیعیه که بهروزرسانی یک محصول، کار سادهای نیست. اما یک فرض ساده رو در نظر بگیرید. مثلا من، یک فروشگاه اینترنتی دارم، قراره در نسخه جدید وبسایتم، بخشی هم افتتاح کنم که افراد بتونن لوازم کارکرده هم خرید و فروش کنن. اضافه کردن یک موجودیت جدید به نرمافزاری که MVC نوشته شده به شدت سادهتر میشه و من فقط لازمه مدل بخش «کارکرده» رو اضافه کنم و روابطش با باقی اجزا رو پیادهسازی کنم.
تسهیل فرایند کشف و رفع باگ : خب از اونجایی که هر موجودیتی، در این معماری به شکلی جدا از موجودیت دیگره، خیلی راحت میشه فهمید مشکل از کجاست. البته لازمه این رو بگم که در معایب هم قراره به این بخش اشاره کنیم و در گوشتون هم میگم که Rest API در این زمینه میتونه بهتر عمل کنه 🙂
خب ما ایرانیا یک ضربالمثل معروف داریم که میگه «گل بیعیب، خداست». پس این معماری و طبیعتا فرمورکهایی که با این معماری کار میکنند هم خالی از ایراد نیستند. در این بخش از معایب MVC میگم و البته بخشیش هم از معایبی که برای ریلز و لاراول گفته شده نقل میکنم.
در مورد بخشی که از ریلز و لاراوله، اسمی از فرمورک نمیارم چون در نظرم این معایب، معایب معماری هستند و نه فرمورک. در واقع اینطوری فرض کنیم که یک سلولی که مشکلی داشته تقسیم شده و همه سلولهای جدید، همون مشکل رو دارند 😁
معایب
سختی درک معماری : این موضوع، میتونه برای برنامهنویسهای تازهکارتر، کمی مشکلساز باشه. توصیه میکنم قبل از این که لقمه بزرگ بردارید و سراغ ریلز، جنگو یا لاراول برید حتما اول با سیناترا، فلاسک یا لومن کار کنید. به این شکل فرمورکها میتونن براتون به شدت قابل درکتر بشن.
خارج شدن شکل نرمافزار از کنترل توسعهدهنده(ها) : این مورد کمی پیچیدهست. فقط بذارید به این شکل بهتون بگم که شما مثلا یه سری واژه رو نمیدونید چطور مدیریت کنید. مثلا ممکنه اسم مدل مربوط به حساب بانکی رو Hesab, Bank یا Bank Account بذارید و نفر بعدی که روی کد شما کار میکنه، با این قضیه به مشکل بخوره. بهترین راه اینه که این موارد، قبل از پیادهسازی کشف و مستند بشن.
انعطاف پایین : طبیعیه که وقتی یک جعبهابزار کامل دم دستتون باشه، دیگه سراغ ساخت ابزار نمیرید. اکثر فرمورکهای MVC هم این مشکل رو دارند و اگر شما بخواهید بخشی هم خودتون پیاده کنید، به شدت به مشکل میخورید.
پرفرمنستایم پایین : خب از اونجایی که اکثر این فرمورکها، دارن همه چیز رو خودشون هندل میکنن، ممکنه هزینه بالایی برای اجرا داشته باشند. البته این هزینه ممکنه با توجه به سختافزارهای امروزی زیاد هم بالا حساب نشه، اما چرا وقتی میشه با کمترین هزینه کاری کرد، هزینه رو بیخود و بیجهت ببریم بالا؟
رفع اشکال پرهزینه : درسته که فرایند کشف و رفع باگ رو گفتیم که آسونه، اما هزینه بالایی داره. حواسمون باید به این موضوع باشه که داریم با چیزی کار میکنیم که همه چیش به همه چیش ربط داره و قطع این ارتباط میتونه هزینه زیادی وارد کنه بهمون.
بزرگ شدن غیرقابل کنترل پروژه : خب وقتی که MVC کار میکنیم، عموما خیلی کم پیش میاد که بخواهیم موجودیتها رو به صورت سرویسهای مجزا توسعه بدیم. در واقع اینجا خبری از میکروسرویس و اینا نیست! همین باعث میشه بیزنس از یک حدی که بزرگتر بشه، کنترلش به شدت سخت شه. از همین رو، معمولا در کنار MVC یک معماری دیگری مثل rest هم استفاده میشه که این داستانها رو نداشته باشیم.
حالا بیاید ببینیم چه راهحلایی برای این قضیه داریم؟ یک راه خیلی خوب اینه که وقتی مدلی ساخته میشه، کنترلر و ویوهای مربوطه هم اتوماتیک تولید بشن. بعدها میتونیم اون چیزی که نیاز نداریم رو از این چرخه حذف کنیم. خب چطوری؟ در این بخش، دو راه حل میارم. یکی از ریلز و دیگری لاراول (فکر کنم کسی انتظار لاراول رو در این قسمت نداشت).
راه حل Ruby on Rails
در ریلز یک مفهومی داریم به اسم scaffold. این مفهوم چی کار میکنه؟ میاد مدل، ویو و کنترلر یه موجودیت رو برای ما میسازه. برای زمانهایی که Rest API نداریم و میخواهیم صفر تا صد اپ رو خودمون بزنیم، یکی از بهترین انتخابها در ساخت و طراحی موجودیتها همینه.
مثال پست بلاگ رو در نظر بگیرید. چطوری میتونیم به سادگی همهچیش رو هندل کنیم؟! سادهست، کافیه این دستور رو تایپ کنیم:
rails generate scaffold Post title:string slug:string body:text
و این دستور به خودی خودش میاد و همه چیزهایی که نیاز داشتیم رو میسازه. خوبیهای این روش چیه؟
استاندارد بودن متدها در کنترلر (یعنی نیاز نیست دیگه زحمت مضاعف برای Routing بکشیم)
وجود viewهایی که پارامترهای درست ارسال و یا دریافت میکنن (کاهش هزینه کشف و رفع باگ در مراحل اولیه توسعه)
اما خب یک بدی بزرگ هم داره و اون اینه که خلاقیت شما رو میتونه کلا نابود کنه. برای اون هم راهکارهایی هست. مثل این که شما یه کنترلر مجزا بسازید و متدها و endpointهای مورد نظر خودتون رو اونجا تعریف کنید.
باقی موارد، همه مثل مطلب قبلیه و خب در مطالبی که در آینده نزدیک خواهم نوشت، حتما اشاره خواهم کرد به این موضوع که چه فعل و انفعالاتی در ریلز رخ میده برای ساخت این ماجراها 🙂
راهحل در لاراول
یک سلب ادعای کوچک ابتدای این بخش بکنم؟ عمده تجربه من با لاراول روی Rest API بوده و فرصتی نشده که MVC باهاش کار کنم. شاید هم هیچوقت MVC کار نکنم. اما این راهحل قطع به یقین برای MVC هم پاسخگوئه.
اول از همه یک مدل میسازیم:
php artisan make:model Post
و خب وارد جزییات نمیشم، میتونیم جزییات مدل رو در فایلهای مربوطه بررسی کنیم.
بعد برای این مدل به این شکل میتونیم کنترلر بسازیم:
البته لازم به ذکره که باید دقت داشته باشید همیشه کنترلرها از جنس resource و CRUD نیستن و این دو راهکار، در واقع برای وقتی خوبن که شما نیازمند CRUD باشید و نخواهید هزینه ساخت کنترلر «از بیخ» رو متحمل بشید.
جمعبندی مطالب
در دو مطلب، هم تعاریف مرتبط با MVC رو یاد گرفتیم، هم یه نیمچه اپ MVC نوشتیم و هم مزایا و معایبش و راهحلهای احتمالی برای معایب قضیه رو بررسی کردیم.
این مطالب، بیش از این که رنگ و بوی برنامهنویسی داشته باشند، مرتبط با مهندسی نرمافزار بودند و خوشحالم که در این زمینه هم محتوایی تولید کردم. فکر کنم این پست دیگه جمعبندی خاصی نیاز نداشته باشه. فقط خواستم بابت وقتی که برای خوندن این مطلب گذاشتید، ازتون تشکر کنم 🙂
وبلاگ شخصی محمدرضا حقیری، برنامهنویس، گیک و یک شخص خوشحال